
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .cache/huggingface/.gitignore +1 -0
- .cache/huggingface/download/.gitattributes.lock +0 -0
- .cache/huggingface/download/.gitattributes.metadata +3 -0
- .cache/huggingface/download/NOTICE.lock +0 -0
- .cache/huggingface/download/NOTICE.metadata +3 -0
- .cache/huggingface/download/README.md.lock +0 -0
- .cache/huggingface/download/README.md.metadata +3 -0
- .cache/huggingface/download/added_tokens.json.lock +0 -0
- .cache/huggingface/download/added_tokens.json.metadata +3 -0
- .cache/huggingface/download/config.json.lock +0 -0
- .cache/huggingface/download/config.json.metadata +3 -0
- .cache/huggingface/download/configuration_aimv2.py.lock +0 -0
- .cache/huggingface/download/configuration_aimv2.py.metadata +3 -0
- .cache/huggingface/download/configuration_ovis.py.lock +0 -0
- .cache/huggingface/download/configuration_ovis.py.metadata +3 -0
- .cache/huggingface/download/generation_config.json.lock +0 -0
- .cache/huggingface/download/generation_config.json.metadata +3 -0
- .cache/huggingface/download/merges.txt.lock +0 -0
- .cache/huggingface/download/merges.txt.metadata +3 -0
- .cache/huggingface/download/model.safetensors.lock +0 -0
- .cache/huggingface/download/model.safetensors.metadata +3 -0
- .cache/huggingface/download/modeling_aimv2.py.lock +0 -0
- .cache/huggingface/download/modeling_aimv2.py.metadata +3 -0
- .cache/huggingface/download/modeling_ovis.py.lock +0 -0
- .cache/huggingface/download/modeling_ovis.py.metadata +3 -0
- .cache/huggingface/download/preprocessor_config.json.lock +0 -0
- .cache/huggingface/download/preprocessor_config.json.metadata +3 -0
- .cache/huggingface/download/special_tokens_map.json.lock +0 -0
- .cache/huggingface/download/special_tokens_map.json.metadata +3 -0
- .cache/huggingface/download/tokenizer.json.lock +0 -0
- .cache/huggingface/download/tokenizer.json.metadata +3 -0
- .cache/huggingface/download/tokenizer_config.json.lock +0 -0
- .cache/huggingface/download/tokenizer_config.json.metadata +3 -0
- .cache/huggingface/download/vocab.json.lock +0 -0
- .cache/huggingface/download/vocab.json.metadata +3 -0
- .gitattributes +1 -0
- NOTICE +14 -0
- README.md +258 -0
- added_tokens.json +32 -0
- config.json +256 -0
- configuration_aimv2.py +63 -0
- configuration_ovis.py +204 -0
- generation_config.json +15 -0
- merges.txt +0 -0
- model.safetensors +3 -0
- modeling_aimv2.py +198 -0
- modeling_ovis.py +590 -0
- preprocessor_config.json +27 -0
- special_tokens_map.json +39 -0
- tokenizer.json +3 -0
.cache/huggingface/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
*
|
.cache/huggingface/download/.gitattributes.lock
ADDED
|
File without changes
|
.cache/huggingface/download/.gitattributes.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
52373fe24473b1aa44333d318f578ae6bf04b49b
|
| 3 |
+
1744020437.949933
|
.cache/huggingface/download/NOTICE.lock
ADDED
|
File without changes
|
.cache/huggingface/download/NOTICE.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
0e3814d458c5165927f99dcd492d361b92aeaa07
|
| 3 |
+
1744020438.074461
|
.cache/huggingface/download/README.md.lock
ADDED
|
File without changes
|
.cache/huggingface/download/README.md.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
6ca32930d9aa4f554c16ffefb5a3826d271f7bd9
|
| 3 |
+
1744020438.045738
|
.cache/huggingface/download/added_tokens.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/added_tokens.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
482ced4679301bf287ebb310bdd1790eb4514232
|
| 3 |
+
1744020438.1181376
|
.cache/huggingface/download/config.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/config.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
605d0602ab0ca6bf0cd8ee4ba94f18b042a5f093
|
| 3 |
+
1744020437.9545557
|
.cache/huggingface/download/configuration_aimv2.py.lock
ADDED
|
File without changes
|
.cache/huggingface/download/configuration_aimv2.py.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
06b2c6d896fbe2be7ca5a2ff32b3057a7d2ec946
|
| 3 |
+
1744020437.9542494
|
.cache/huggingface/download/configuration_ovis.py.lock
ADDED
|
File without changes
|
.cache/huggingface/download/configuration_ovis.py.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
b094185a4218ae2bccb58ccf481c894164d8479f
|
| 3 |
+
1744020438.0111387
|
.cache/huggingface/download/generation_config.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/generation_config.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
62dec5ceb087a8f3702c4a301495a7215d072ce7
|
| 3 |
+
1744020438.2107105
|
.cache/huggingface/download/merges.txt.lock
ADDED
|
File without changes
|
.cache/huggingface/download/merges.txt.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
31349551d90c7606f325fe0f11bbb8bd5fa0d7c7
|
| 3 |
+
1744020439.931449
|
.cache/huggingface/download/model.safetensors.lock
ADDED
|
File without changes
|
.cache/huggingface/download/model.safetensors.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
8a25670ed919d7cc9fad1fa4a359b3da5a0b744eab448a498d6c23cdc8b9edc2
|
| 3 |
+
1744020927.641807
|
.cache/huggingface/download/modeling_aimv2.py.lock
ADDED
|
File without changes
|
.cache/huggingface/download/modeling_aimv2.py.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
773b8cdad42fef5692dfcf0e837f18d150613d91
|
| 3 |
+
1744020439.1234415
|
.cache/huggingface/download/modeling_ovis.py.lock
ADDED
|
File without changes
|
.cache/huggingface/download/modeling_ovis.py.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
8288613495aaae374749d6e387d8c1a1437997f9
|
| 3 |
+
1744020439.0775173
|
.cache/huggingface/download/preprocessor_config.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/preprocessor_config.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
91bd2284ac30e92dc70023899547f700e542a911
|
| 3 |
+
1744020439.146727
|
.cache/huggingface/download/special_tokens_map.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/special_tokens_map.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
ac23c0aaa2434523c494330aeb79c58395378103
|
| 3 |
+
1744020439.3326318
|
.cache/huggingface/download/tokenizer.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/tokenizer.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
9c5ae00e602b8860cbd784ba82a8aa14e8feecec692e7076590d014d7b7fdafa
|
| 3 |
+
1744020444.7309973
|
.cache/huggingface/download/tokenizer_config.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/tokenizer_config.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
8adf747ccaf85ff9587338cee6ed6be027b98210
|
| 3 |
+
1744020439.3145587
|
.cache/huggingface/download/vocab.json.lock
ADDED
|
File without changes
|
.cache/huggingface/download/vocab.json.metadata
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
b5c50bc2836fd46a6cd0feb39269eeb5968fac1d
|
| 2 |
+
4783fe10ac3adce15ac8f358ef5462739852c569
|
| 3 |
+
1744020443.0863569
|
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
NOTICE
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (C) 2025 AIDC-AI
|
| 2 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
you may not use this file except in compliance with the License.
|
| 4 |
+
You may obtain a copy of the License at
|
| 5 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
See the License for the specific language governing permissions and
|
| 10 |
+
limitations under the License.
|
| 11 |
+
|
| 12 |
+
This model was trained based on the following models:
|
| 13 |
+
1. Qwen2.5 (https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct), license:(https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct/blob/main/LICENSE, SPDX-License-identifier: Apache-2.0).
|
| 14 |
+
2. AimV2 (https://huggingface.co/apple/aimv2-large-patch14-448), license: Apple-Sample-Code-License (https://developer.apple.com/support/downloads/terms/apple-sample-code/Apple-Sample-Code-License.pdf)
|
README.md
ADDED
|
@@ -0,0 +1,258 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- AIDC-AI/Ovis-dataset
|
| 5 |
+
library_name: transformers
|
| 6 |
+
tags:
|
| 7 |
+
- MLLM
|
| 8 |
+
pipeline_tag: image-text-to-text
|
| 9 |
+
language:
|
| 10 |
+
- en
|
| 11 |
+
- zh
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
# Ovis2-1B
|
| 15 |
+
<div align="center">
|
| 16 |
+
<img src=https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/3IK823BZ8w-mz_QfeYkDn.png width="30%"/>
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
## Introduction
|
| 20 |
+
[GitHub](https://github.com/AIDC-AI/Ovis) | [Paper](https://arxiv.org/abs/2405.20797)
|
| 21 |
+
|
| 22 |
+
We are pleased to announce the release of **Ovis2**, our latest advancement in multi-modal large language models (MLLMs). Ovis2 inherits the innovative architectural design of the Ovis series, aimed at structurally aligning visual and textual embeddings. As the successor to Ovis1.6, Ovis2 incorporates significant improvements in both dataset curation and training methodologies.
|
| 23 |
+
|
| 24 |
+
**Key Features**:
|
| 25 |
+
|
| 26 |
+
- **Small Model Performance**: Optimized training strategies enable small-scale models to achieve higher capability density, demonstrating cross-tier leading advantages.
|
| 27 |
+
|
| 28 |
+
- **Enhanced Reasoning Capabilities**: Significantly strengthens Chain-of-Thought (CoT) reasoning abilities through the combination of instruction tuning and preference learning.
|
| 29 |
+
|
| 30 |
+
- **Video and Multi-Image Processing**: Video and multi-image data are incorporated into training to enhance the ability to handle complex visual information across frames and images.
|
| 31 |
+
|
| 32 |
+
- **Multilingual Support and OCR**: Enhances multilingual OCR beyond English and Chinese and improves structured data extraction from complex visual elements like tables and charts.
|
| 33 |
+
|
| 34 |
+
<div align="center">
|
| 35 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/XB-vgzDL6FshrSNGyZvzc.png" width="100%" />
|
| 36 |
+
</div>
|
| 37 |
+
|
| 38 |
+
## Model Zoo
|
| 39 |
+
|
| 40 |
+
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|
| 41 |
+
|:-----------|:-----------------------:|:---------------------:|:-------------------------------------------------------:|:--------------------------------------------------------:|
|
| 42 |
+
| Ovis2-1B | aimv2-large-patch14-448 | Qwen2.5-0.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-1B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-1B) |
|
| 43 |
+
| Ovis2-2B | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-2B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-2B) |
|
| 44 |
+
| Ovis2-4B | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-4B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-4B) |
|
| 45 |
+
| Ovis2-8B | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-8B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-8B) |
|
| 46 |
+
| Ovis2-16B | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-16B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-16B) |
|
| 47 |
+
| Ovis2-34B | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-34B) | - |
|
| 48 |
+
|
| 49 |
+
## Performance
|
| 50 |
+
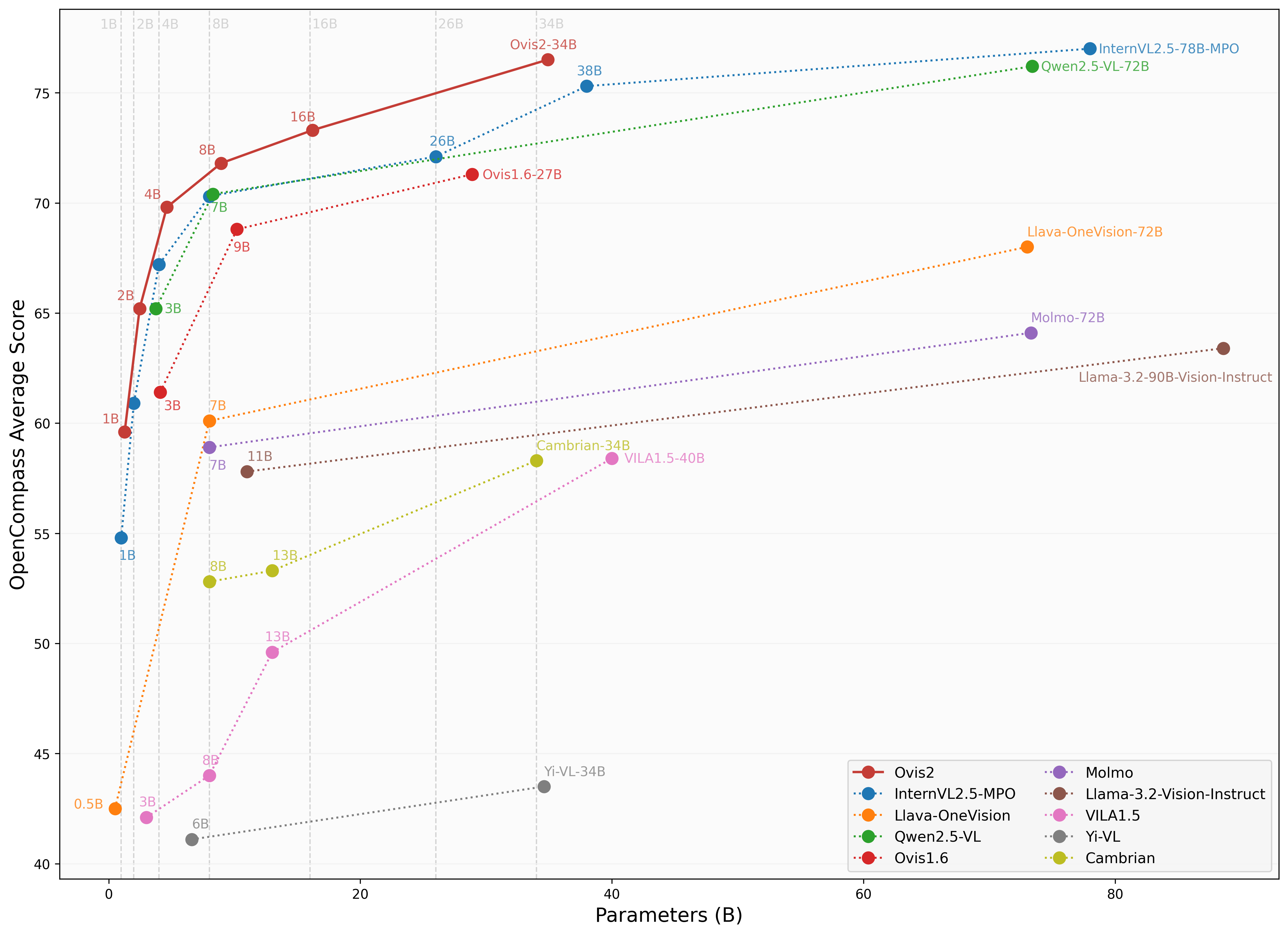
We use [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), as employed in the OpenCompass [multimodal](https://rank.opencompass.org.cn/leaderboard-multimodal) and [reasoning](https://rank.opencompass.org.cn/leaderboard-multimodal-reasoning) leaderboard, to evaluate Ovis2.
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
### Image Benchmark
|
| 55 |
+
| Benchmark | Qwen2.5-VL-3B | SAIL-VL-2B | InternVL2.5-2B-MPO | Ovis1.6-3B | InternVL2.5-1B-MPO | Ovis2-1B | Ovis2-2B |
|
| 56 |
+
|:-----------------------------|:---------------:|:------------:|:--------------------:|:------------:|:--------------------:|:----------:|:----------:|
|
| 57 |
+
| MMBench-V1.1<sub>test</sub> | **77.1** | 73.6 | 70.7 | 74.1 | 65.8 | 68.4 | 76.9 |
|
| 58 |
+
| MMStar | 56.5 | 56.5 | 54.9 | 52.0 | 49.5 | 52.1 | **56.7** |
|
| 59 |
+
| MMMU<sub>val</sub> | **51.4** | 44.1 | 44.6 | 46.7 | 40.3 | 36.1 | 45.6 |
|
| 60 |
+
| MathVista<sub>testmini</sub> | 60.1 | 62.8 | 53.4 | 58.9 | 47.7 | 59.4 | **64.1** |
|
| 61 |
+
| HallusionBench | 48.7 | 45.9 | 40.7 | 43.8 | 34.8 | 45.2 | **50.2** |
|
| 62 |
+
| AI2D | 81.4 | 77.4 | 75.1 | 77.8 | 68.5 | 76.4 | **82.7** |
|
| 63 |
+
| OCRBench | 83.1 | 83.1 | 83.8 | 80.1 | 84.3 | **89.0** | 87.3 |
|
| 64 |
+
| MMVet | 63.2 | 44.2 | **64.2** | 57.6 | 47.2 | 50.0 | 58.3 |
|
| 65 |
+
| MMBench<sub>test</sub> | 78.6 | 77 | 72.8 | 76.6 | 67.9 | 70.2 | **78.9** |
|
| 66 |
+
| MMT-Bench<sub>val</sub> | 60.8 | 57.1 | 54.4 | 59.2 | 50.8 | 55.5 | **61.7** |
|
| 67 |
+
| RealWorldQA | 66.5 | 62 | 61.3 | **66.7** | 57 | 63.9 | 66.0 |
|
| 68 |
+
| BLINK | **48.4** | 46.4 | 43.8 | 43.8 | 41 | 44.0 | 47.9 |
|
| 69 |
+
| QBench | 74.4 | 72.8 | 69.8 | 75.8 | 63.3 | 71.3 | **76.2** |
|
| 70 |
+
| ABench | 75.5 | 74.5 | 71.1 | 75.2 | 67.5 | 71.3 | **76.6** |
|
| 71 |
+
| MTVQA | 24.9 | 20.2 | 22.6 | 21.1 | 21.7 | 23.7 | **25.6** |
|
| 72 |
+
|
| 73 |
+
### Video Benchmark
|
| 74 |
+
| Benchmark | Qwen2.5-VL-3B | InternVL2.5-2B | InternVL2.5-1B | Ovis2-1B | Ovis2-2B |
|
| 75 |
+
| ------------------- |:-------------:|:--------------:|:--------------:|:---------:|:-------------:|
|
| 76 |
+
| VideoMME(wo/w-subs) | **61.5/67.6** | 51.9 / 54.1 | 50.3 / 52.3 | 48.6/49.5 | 57.2/60.8 |
|
| 77 |
+
| MVBench | 67.0 | **68.8** | 64.3 | 60.32 | 64.9 |
|
| 78 |
+
| MLVU(M-Avg/G-Avg) | 68.2/- | 61.4/- | 57.3/- | 58.5/3.66 | **68.6**/3.86 |
|
| 79 |
+
| MMBench-Video | **1.63** | 1.44 | 1.36 | 1.26 | 1.57 |
|
| 80 |
+
| TempCompass | **64.4** | - | - | 51.43 | 62.64 |
|
| 81 |
+
|
| 82 |
+
## Usage
|
| 83 |
+
Below is a code snippet demonstrating how to run Ovis with various input types. For additional usage instructions, including inference wrapper and Gradio UI, please refer to [Ovis GitHub](https://github.com/AIDC-AI/Ovis?tab=readme-ov-file#inference).
|
| 84 |
+
```bash
|
| 85 |
+
pip install torch==2.4.0 transformers==4.46.2 numpy==1.25.0 pillow==10.3.0
|
| 86 |
+
pip install flash-attn==2.7.0.post2 --no-build-isolation
|
| 87 |
+
```
|
| 88 |
+
```python
|
| 89 |
+
import torch
|
| 90 |
+
from PIL import Image
|
| 91 |
+
from transformers import AutoModelForCausalLM
|
| 92 |
+
|
| 93 |
+
# load model
|
| 94 |
+
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
|
| 95 |
+
torch_dtype=torch.bfloat16,
|
| 96 |
+
multimodal_max_length=32768,
|
| 97 |
+
trust_remote_code=True).cuda()
|
| 98 |
+
text_tokenizer = model.get_text_tokenizer()
|
| 99 |
+
visual_tokenizer = model.get_visual_tokenizer()
|
| 100 |
+
|
| 101 |
+
# single-image input
|
| 102 |
+
image_path = '/data/images/example_1.jpg'
|
| 103 |
+
images = [Image.open(image_path)]
|
| 104 |
+
max_partition = 9
|
| 105 |
+
text = 'Describe the image.'
|
| 106 |
+
query = f'<image>\n{text}'
|
| 107 |
+
|
| 108 |
+
## cot-style input
|
| 109 |
+
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
|
| 110 |
+
# image_path = '/data/images/example_1.jpg'
|
| 111 |
+
# images = [Image.open(image_path)]
|
| 112 |
+
# max_partition = 9
|
| 113 |
+
# text = "What's the area of the shape?"
|
| 114 |
+
# query = f'<image>\n{text}\n{cot_suffix}'
|
| 115 |
+
|
| 116 |
+
## multiple-images input
|
| 117 |
+
# image_paths = [
|
| 118 |
+
# '/data/images/example_1.jpg',
|
| 119 |
+
# '/data/images/example_2.jpg',
|
| 120 |
+
# '/data/images/example_3.jpg'
|
| 121 |
+
# ]
|
| 122 |
+
# images = [Image.open(image_path) for image_path in image_paths]
|
| 123 |
+
# max_partition = 4
|
| 124 |
+
# text = 'Describe each image.'
|
| 125 |
+
# query = '\n'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '\n' + text
|
| 126 |
+
|
| 127 |
+
## video input (require `pip install moviepy==1.0.3`)
|
| 128 |
+
# from moviepy.editor import VideoFileClip
|
| 129 |
+
# video_path = '/data/videos/example_1.mp4'
|
| 130 |
+
# num_frames = 12
|
| 131 |
+
# max_partition = 1
|
| 132 |
+
# text = 'Describe the video.'
|
| 133 |
+
# with VideoFileClip(video_path) as clip:
|
| 134 |
+
# total_frames = int(clip.fps * clip.duration)
|
| 135 |
+
# if total_frames <= num_frames:
|
| 136 |
+
# sampled_indices = range(total_frames)
|
| 137 |
+
# else:
|
| 138 |
+
# stride = total_frames / num_frames
|
| 139 |
+
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
|
| 140 |
+
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
|
| 141 |
+
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
|
| 142 |
+
# images = frames
|
| 143 |
+
# query = '\n'.join(['<image>'] * len(images)) + '\n' + text
|
| 144 |
+
|
| 145 |
+
## text-only input
|
| 146 |
+
# images = []
|
| 147 |
+
# max_partition = None
|
| 148 |
+
# text = 'Hello'
|
| 149 |
+
# query = text
|
| 150 |
+
|
| 151 |
+
# format conversation
|
| 152 |
+
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
|
| 153 |
+
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
|
| 154 |
+
input_ids = input_ids.unsqueeze(0).to(device=model.device)
|
| 155 |
+
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
|
| 156 |
+
if pixel_values is not None:
|
| 157 |
+
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
|
| 158 |
+
pixel_values = [pixel_values]
|
| 159 |
+
|
| 160 |
+
# generate output
|
| 161 |
+
with torch.inference_mode():
|
| 162 |
+
gen_kwargs = dict(
|
| 163 |
+
max_new_tokens=1024,
|
| 164 |
+
do_sample=False,
|
| 165 |
+
top_p=None,
|
| 166 |
+
top_k=None,
|
| 167 |
+
temperature=None,
|
| 168 |
+
repetition_penalty=None,
|
| 169 |
+
eos_token_id=model.generation_config.eos_token_id,
|
| 170 |
+
pad_token_id=text_tokenizer.pad_token_id,
|
| 171 |
+
use_cache=True
|
| 172 |
+
)
|
| 173 |
+
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
|
| 174 |
+
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
|
| 175 |
+
print(f'Output:\n{output}')
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
<details>
|
| 179 |
+
<summary>Batch Inference</summary>
|
| 180 |
+
|
| 181 |
+
```python
|
| 182 |
+
import torch
|
| 183 |
+
from PIL import Image
|
| 184 |
+
from transformers import AutoModelForCausalLM
|
| 185 |
+
|
| 186 |
+
# load model
|
| 187 |
+
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
|
| 188 |
+
torch_dtype=torch.bfloat16,
|
| 189 |
+
multimodal_max_length=32768,
|
| 190 |
+
trust_remote_code=True).cuda()
|
| 191 |
+
text_tokenizer = model.get_text_tokenizer()
|
| 192 |
+
visual_tokenizer = model.get_visual_tokenizer()
|
| 193 |
+
|
| 194 |
+
# preprocess inputs
|
| 195 |
+
batch_inputs = [
|
| 196 |
+
('/data/images/example_1.jpg', 'What colors dominate the image?'),
|
| 197 |
+
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
|
| 198 |
+
('/data/images/example_3.jpg', 'Is there any text in the image?')
|
| 199 |
+
]
|
| 200 |
+
|
| 201 |
+
batch_input_ids = []
|
| 202 |
+
batch_attention_mask = []
|
| 203 |
+
batch_pixel_values = []
|
| 204 |
+
|
| 205 |
+
for image_path, text in batch_inputs:
|
| 206 |
+
image = Image.open(image_path)
|
| 207 |
+
query = f'<image>\n{text}'
|
| 208 |
+
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
|
| 209 |
+
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
|
| 210 |
+
batch_input_ids.append(input_ids.to(device=model.device))
|
| 211 |
+
batch_attention_mask.append(attention_mask.to(device=model.device))
|
| 212 |
+
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
|
| 213 |
+
|
| 214 |
+
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
|
| 215 |
+
padding_value=0.0).flip(dims=[1])
|
| 216 |
+
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
|
| 217 |
+
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
|
| 218 |
+
batch_first=True, padding_value=False).flip(dims=[1])
|
| 219 |
+
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
|
| 220 |
+
|
| 221 |
+
# generate outputs
|
| 222 |
+
with torch.inference_mode():
|
| 223 |
+
gen_kwargs = dict(
|
| 224 |
+
max_new_tokens=1024,
|
| 225 |
+
do_sample=False,
|
| 226 |
+
top_p=None,
|
| 227 |
+
top_k=None,
|
| 228 |
+
temperature=None,
|
| 229 |
+
repetition_penalty=None,
|
| 230 |
+
eos_token_id=model.generation_config.eos_token_id,
|
| 231 |
+
pad_token_id=text_tokenizer.pad_token_id,
|
| 232 |
+
use_cache=True
|
| 233 |
+
)
|
| 234 |
+
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
|
| 235 |
+
**gen_kwargs)
|
| 236 |
+
|
| 237 |
+
for i in range(len(batch_inputs)):
|
| 238 |
+
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
|
| 239 |
+
print(f'Output {i + 1}:\n{output}\n')
|
| 240 |
+
```
|
| 241 |
+
</details>
|
| 242 |
+
|
| 243 |
+
## Citation
|
| 244 |
+
If you find Ovis useful, please consider citing the paper
|
| 245 |
+
```
|
| 246 |
+
@article{lu2024ovis,
|
| 247 |
+
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
|
| 248 |
+
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
|
| 249 |
+
year={2024},
|
| 250 |
+
journal={arXiv:2405.20797}
|
| 251 |
+
}
|
| 252 |
+
```
|
| 253 |
+
|
| 254 |
+
## License
|
| 255 |
+
This project is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt) (SPDX-License-Identifier: Apache-2.0).
|
| 256 |
+
|
| 257 |
+
## Disclaimer
|
| 258 |
+
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</tool_call>": 151658,
|
| 3 |
+
"<tool_call>": 151657,
|
| 4 |
+
"<|box_end|>": 151649,
|
| 5 |
+
"<|box_start|>": 151648,
|
| 6 |
+
"<|endoftext|>": 151643,
|
| 7 |
+
"<|file_sep|>": 151664,
|
| 8 |
+
"<|fim_middle|>": 151660,
|
| 9 |
+
"<|fim_pad|>": 151662,
|
| 10 |
+
"<|fim_prefix|>": 151659,
|
| 11 |
+
"<|fim_suffix|>": 151661,
|
| 12 |
+
"<|im_end|>": 151645,
|
| 13 |
+
"<|im_start|>": 151644,
|
| 14 |
+
"<|image_pad|>": 151655,
|
| 15 |
+
"<|object_ref_end|>": 151647,
|
| 16 |
+
"<|object_ref_start|>": 151646,
|
| 17 |
+
"<|quad_end|>": 151651,
|
| 18 |
+
"<|quad_start|>": 151650,
|
| 19 |
+
"<|repo_name|>": 151663,
|
| 20 |
+
"<|video_pad|>": 151656,
|
| 21 |
+
"<|vision_end|>": 151653,
|
| 22 |
+
"<|vision_pad|>": 151654,
|
| 23 |
+
"<|vision_start|>": 151652,
|
| 24 |
+
"<col>": 151669,
|
| 25 |
+
"<image>": 151665,
|
| 26 |
+
"<image_atom>": 151666,
|
| 27 |
+
"<image_pad>": 151672,
|
| 28 |
+
"<img>": 151667,
|
| 29 |
+
"<pre>": 151668,
|
| 30 |
+
"<row>": 151670,
|
| 31 |
+
"</img>": 151671
|
| 32 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,256 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Ovis"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "configuration_ovis.OvisConfig",
|
| 7 |
+
"AutoModelForCausalLM": "modeling_ovis.Ovis"
|
| 8 |
+
},
|
| 9 |
+
"conversation_formatter_class": "QwenConversationFormatter",
|
| 10 |
+
"disable_tie_weight": false,
|
| 11 |
+
"hidden_size": 896,
|
| 12 |
+
"llm_attn_implementation": "flash_attention_2",
|
| 13 |
+
"llm_config": {
|
| 14 |
+
"_attn_implementation_autoset": true,
|
| 15 |
+
"_name_or_path": "Qwen/Qwen2.5-0.5B-Instruct",
|
| 16 |
+
"add_cross_attention": false,
|
| 17 |
+
"architectures": [
|
| 18 |
+
"Qwen2ForCausalLM"
|
| 19 |
+
],
|
| 20 |
+
"attention_dropout": 0.0,
|
| 21 |
+
"bad_words_ids": null,
|
| 22 |
+
"begin_suppress_tokens": null,
|
| 23 |
+
"bos_token_id": 151643,
|
| 24 |
+
"chunk_size_feed_forward": 0,
|
| 25 |
+
"cross_attention_hidden_size": null,
|
| 26 |
+
"decoder_start_token_id": null,
|
| 27 |
+
"diversity_penalty": 0.0,
|
| 28 |
+
"do_sample": false,
|
| 29 |
+
"early_stopping": false,
|
| 30 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 31 |
+
"eos_token_id": 151645,
|
| 32 |
+
"exponential_decay_length_penalty": null,
|
| 33 |
+
"finetuning_task": null,
|
| 34 |
+
"forced_bos_token_id": null,
|
| 35 |
+
"forced_eos_token_id": null,
|
| 36 |
+
"hidden_act": "silu",
|
| 37 |
+
"hidden_size": 896,
|
| 38 |
+
"id2label": {
|
| 39 |
+
"0": "LABEL_0",
|
| 40 |
+
"1": "LABEL_1"
|
| 41 |
+
},
|
| 42 |
+
"initializer_range": 0.02,
|
| 43 |
+
"intermediate_size": 4864,
|
| 44 |
+
"is_decoder": false,
|
| 45 |
+
"is_encoder_decoder": false,
|
| 46 |
+
"label2id": {
|
| 47 |
+
"LABEL_0": 0,
|
| 48 |
+
"LABEL_1": 1
|
| 49 |
+
},
|
| 50 |
+
"length_penalty": 1.0,
|
| 51 |
+
"max_length": 20,
|
| 52 |
+
"max_position_embeddings": 32768,
|
| 53 |
+
"max_window_layers": 21,
|
| 54 |
+
"min_length": 0,
|
| 55 |
+
"model_type": "qwen2",
|
| 56 |
+
"no_repeat_ngram_size": 0,
|
| 57 |
+
"num_attention_heads": 14,
|
| 58 |
+
"num_beam_groups": 1,
|
| 59 |
+
"num_beams": 1,
|
| 60 |
+
"num_hidden_layers": 24,
|
| 61 |
+
"num_key_value_heads": 2,
|
| 62 |
+
"num_return_sequences": 1,
|
| 63 |
+
"output_attentions": false,
|
| 64 |
+
"output_hidden_states": false,
|
| 65 |
+
"output_scores": false,
|
| 66 |
+
"pad_token_id": null,
|
| 67 |
+
"prefix": null,
|
| 68 |
+
"problem_type": null,
|
| 69 |
+
"pruned_heads": {},
|
| 70 |
+
"remove_invalid_values": false,
|
| 71 |
+
"repetition_penalty": 1.0,
|
| 72 |
+
"return_dict": true,
|
| 73 |
+
"return_dict_in_generate": false,
|
| 74 |
+
"rms_norm_eps": 1e-06,
|
| 75 |
+
"rope_scaling": null,
|
| 76 |
+
"rope_theta": 1000000.0,
|
| 77 |
+
"sep_token_id": null,
|
| 78 |
+
"sliding_window": null,
|
| 79 |
+
"suppress_tokens": null,
|
| 80 |
+
"task_specific_params": null,
|
| 81 |
+
"temperature": 1.0,
|
| 82 |
+
"tf_legacy_loss": false,
|
| 83 |
+
"tie_encoder_decoder": false,
|
| 84 |
+
"tie_word_embeddings": true,
|
| 85 |
+
"tokenizer_class": null,
|
| 86 |
+
"top_k": 50,
|
| 87 |
+
"top_p": 1.0,
|
| 88 |
+
"torch_dtype": "bfloat16",
|
| 89 |
+
"torchscript": false,
|
| 90 |
+
"typical_p": 1.0,
|
| 91 |
+
"use_bfloat16": false,
|
| 92 |
+
"use_cache": true,
|
| 93 |
+
"use_sliding_window": false,
|
| 94 |
+
"vocab_size": 151936
|
| 95 |
+
},
|
| 96 |
+
"model_type": "ovis",
|
| 97 |
+
"multimodal_max_length": 32768,
|
| 98 |
+
"torch_dtype": "bfloat16",
|
| 99 |
+
"transformers_version": "4.46.2",
|
| 100 |
+
"use_cache": true,
|
| 101 |
+
"visual_tokenizer_config": {
|
| 102 |
+
"_attn_implementation_autoset": true,
|
| 103 |
+
"_name_or_path": "",
|
| 104 |
+
"add_cross_attention": false,
|
| 105 |
+
"architectures": null,
|
| 106 |
+
"backbone_config": {
|
| 107 |
+
"_attn_implementation_autoset": true,
|
| 108 |
+
"_name_or_path": "apple/aimv2-large-patch14-448",
|
| 109 |
+
"add_cross_attention": false,
|
| 110 |
+
"architectures": [
|
| 111 |
+
"AIMv2Model"
|
| 112 |
+
],
|
| 113 |
+
"attention_dropout": 0.0,
|
| 114 |
+
"auto_map": {
|
| 115 |
+
"AutoConfig": "configuration_aimv2.AIMv2Config",
|
| 116 |
+
"AutoModel": "modeling_aimv2.AIMv2Model",
|
| 117 |
+
"FlaxAutoModel": "modeling_flax_aimv2.FlaxAIMv2Model"
|
| 118 |
+
},
|
| 119 |
+
"bad_words_ids": null,
|
| 120 |
+
"begin_suppress_tokens": null,
|
| 121 |
+
"bos_token_id": null,
|
| 122 |
+
"chunk_size_feed_forward": 0,
|
| 123 |
+
"cross_attention_hidden_size": null,
|
| 124 |
+
"decoder_start_token_id": null,
|
| 125 |
+
"diversity_penalty": 0.0,
|
| 126 |
+
"do_sample": false,
|
| 127 |
+
"early_stopping": false,
|
| 128 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 129 |
+
"eos_token_id": null,
|
| 130 |
+
"exponential_decay_length_penalty": null,
|
| 131 |
+
"finetuning_task": null,
|
| 132 |
+
"forced_bos_token_id": null,
|
| 133 |
+
"forced_eos_token_id": null,
|
| 134 |
+
"hidden_size": 1024,
|
| 135 |
+
"id2label": {
|
| 136 |
+
"0": "LABEL_0",
|
| 137 |
+
"1": "LABEL_1"
|
| 138 |
+
},
|
| 139 |
+
"image_size": 448,
|
| 140 |
+
"intermediate_size": 2816,
|
| 141 |
+
"is_decoder": false,
|
| 142 |
+
"is_encoder_decoder": false,
|
| 143 |
+
"label2id": {
|
| 144 |
+
"LABEL_0": 0,
|
| 145 |
+
"LABEL_1": 1
|
| 146 |
+
},
|
| 147 |
+
"length_penalty": 1.0,
|
| 148 |
+
"max_length": 20,
|
| 149 |
+
"min_length": 0,
|
| 150 |
+
"model_type": "aimv2",
|
| 151 |
+
"no_repeat_ngram_size": 0,
|
| 152 |
+
"num_attention_heads": 8,
|
| 153 |
+
"num_beam_groups": 1,
|
| 154 |
+
"num_beams": 1,
|
| 155 |
+
"num_channels": 3,
|
| 156 |
+
"num_hidden_layers": 24,
|
| 157 |
+
"num_return_sequences": 1,
|
| 158 |
+
"output_attentions": false,
|
| 159 |
+
"output_hidden_states": false,
|
| 160 |
+
"output_scores": false,
|
| 161 |
+
"pad_token_id": null,
|
| 162 |
+
"patch_size": 14,
|
| 163 |
+
"prefix": null,
|
| 164 |
+
"problem_type": null,
|
| 165 |
+
"projection_dropout": 0.0,
|
| 166 |
+
"pruned_heads": {},
|
| 167 |
+
"qkv_bias": false,
|
| 168 |
+
"remove_invalid_values": false,
|
| 169 |
+
"repetition_penalty": 1.0,
|
| 170 |
+
"return_dict": true,
|
| 171 |
+
"return_dict_in_generate": false,
|
| 172 |
+
"rms_norm_eps": 1e-05,
|
| 173 |
+
"sep_token_id": null,
|
| 174 |
+
"suppress_tokens": null,
|
| 175 |
+
"task_specific_params": null,
|
| 176 |
+
"temperature": 1.0,
|
| 177 |
+
"tf_legacy_loss": false,
|
| 178 |
+
"tie_encoder_decoder": false,
|
| 179 |
+
"tie_word_embeddings": true,
|
| 180 |
+
"tokenizer_class": null,
|
| 181 |
+
"top_k": 50,
|
| 182 |
+
"top_p": 1.0,
|
| 183 |
+
"torch_dtype": "bfloat16",
|
| 184 |
+
"torchscript": false,
|
| 185 |
+
"typical_p": 1.0,
|
| 186 |
+
"use_bfloat16": false,
|
| 187 |
+
"use_bias": false
|
| 188 |
+
},
|
| 189 |
+
"backbone_kwargs": {},
|
| 190 |
+
"bad_words_ids": null,
|
| 191 |
+
"begin_suppress_tokens": null,
|
| 192 |
+
"bos_token_id": null,
|
| 193 |
+
"chunk_size_feed_forward": 0,
|
| 194 |
+
"cross_attention_hidden_size": null,
|
| 195 |
+
"decoder_start_token_id": null,
|
| 196 |
+
"depths": null,
|
| 197 |
+
"diversity_penalty": 0.0,
|
| 198 |
+
"do_sample": false,
|
| 199 |
+
"drop_cls_token": false,
|
| 200 |
+
"early_stopping": false,
|
| 201 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 202 |
+
"eos_token_id": null,
|
| 203 |
+
"exponential_decay_length_penalty": null,
|
| 204 |
+
"finetuning_task": null,
|
| 205 |
+
"forced_bos_token_id": null,
|
| 206 |
+
"forced_eos_token_id": null,
|
| 207 |
+
"hidden_stride": 2,
|
| 208 |
+
"id2label": {
|
| 209 |
+
"0": "LABEL_0",
|
| 210 |
+
"1": "LABEL_1"
|
| 211 |
+
},
|
| 212 |
+
"is_decoder": false,
|
| 213 |
+
"is_encoder_decoder": false,
|
| 214 |
+
"label2id": {
|
| 215 |
+
"LABEL_0": 0,
|
| 216 |
+
"LABEL_1": 1
|
| 217 |
+
},
|
| 218 |
+
"length_penalty": 1.0,
|
| 219 |
+
"max_length": 20,
|
| 220 |
+
"min_length": 0,
|
| 221 |
+
"model_type": "aimv2_visual_tokenizer",
|
| 222 |
+
"no_repeat_ngram_size": 0,
|
| 223 |
+
"num_beam_groups": 1,
|
| 224 |
+
"num_beams": 1,
|
| 225 |
+
"num_return_sequences": 1,
|
| 226 |
+
"output_attentions": false,
|
| 227 |
+
"output_hidden_states": false,
|
| 228 |
+
"output_scores": false,
|
| 229 |
+
"pad_token_id": null,
|
| 230 |
+
"prefix": null,
|
| 231 |
+
"problem_type": null,
|
| 232 |
+
"pruned_heads": {},
|
| 233 |
+
"remove_invalid_values": false,
|
| 234 |
+
"repetition_penalty": 1.0,
|
| 235 |
+
"return_dict": true,
|
| 236 |
+
"return_dict_in_generate": false,
|
| 237 |
+
"sep_token_id": null,
|
| 238 |
+
"suppress_tokens": null,
|
| 239 |
+
"task_specific_params": null,
|
| 240 |
+
"tau": 1.0,
|
| 241 |
+
"temperature": 1.0,
|
| 242 |
+
"tf_legacy_loss": false,
|
| 243 |
+
"tie_encoder_decoder": false,
|
| 244 |
+
"tie_word_embeddings": true,
|
| 245 |
+
"tokenize_function": "softmax",
|
| 246 |
+
"tokenizer_class": null,
|
| 247 |
+
"top_k": 50,
|
| 248 |
+
"top_p": 1.0,
|
| 249 |
+
"torch_dtype": null,
|
| 250 |
+
"torchscript": false,
|
| 251 |
+
"typical_p": 1.0,
|
| 252 |
+
"use_bfloat16": false,
|
| 253 |
+
"use_indicators": false,
|
| 254 |
+
"vocab_size": 65536
|
| 255 |
+
}
|
| 256 |
+
}
|
configuration_aimv2.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# copied from https://huggingface.co/apple/aimv2-huge-patch14-448
|
| 2 |
+
from typing import Any
|
| 3 |
+
|
| 4 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 5 |
+
|
| 6 |
+
__all__ = ["AIMv2Config"]
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class AIMv2Config(PretrainedConfig):
|
| 10 |
+
"""This is the configuration class to store the configuration of an [`AIMv2Model`].
|
| 11 |
+
|
| 12 |
+
Instantiating a configuration with the defaults will yield a similar configuration
|
| 13 |
+
to that of the [apple/aimv2-large-patch14-224](https://huggingface.co/apple/aimv2-large-patch14-224).
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
hidden_size: Dimension of the hidden representations.
|
| 17 |
+
intermediate_size: Dimension of the SwiGLU representations.
|
| 18 |
+
num_hidden_layers: Number of hidden layers in the Transformer.
|
| 19 |
+
num_attention_heads: Number of attention heads for each attention layer
|
| 20 |
+
in the Transformer.
|
| 21 |
+
num_channels: Number of input channels.
|
| 22 |
+
image_size: Image size.
|
| 23 |
+
patch_size: Patch size.
|
| 24 |
+
rms_norm_eps: Epsilon value used for the RMS normalization layer.
|
| 25 |
+
attention_dropout: Dropout ratio for attention probabilities.
|
| 26 |
+
projection_dropout: Dropout ratio for the projection layer after the attention.
|
| 27 |
+
qkv_bias: Whether to add a bias to the queries, keys and values.
|
| 28 |
+
use_bias: Whether to add a bias in the feed-forward and projection layers.
|
| 29 |
+
kwargs: Keyword arguments for the [`PretrainedConfig`].
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
model_type: str = "aimv2"
|
| 33 |
+
|
| 34 |
+
def __init__(
|
| 35 |
+
self,
|
| 36 |
+
hidden_size: int = 1024,
|
| 37 |
+
intermediate_size: int = 2816,
|
| 38 |
+
num_hidden_layers: int = 24,
|
| 39 |
+
num_attention_heads: int = 8,
|
| 40 |
+
num_channels: int = 3,
|
| 41 |
+
image_size: int = 224,
|
| 42 |
+
patch_size: int = 14,
|
| 43 |
+
rms_norm_eps: float = 1e-5,
|
| 44 |
+
attention_dropout: float = 0.0,
|
| 45 |
+
projection_dropout: float = 0.0,
|
| 46 |
+
qkv_bias: bool = False,
|
| 47 |
+
use_bias: bool = False,
|
| 48 |
+
**kwargs: Any,
|
| 49 |
+
):
|
| 50 |
+
super().__init__(**kwargs)
|
| 51 |
+
self.hidden_size = hidden_size
|
| 52 |
+
self.intermediate_size = intermediate_size
|
| 53 |
+
self.num_hidden_layers = num_hidden_layers
|
| 54 |
+
self.num_attention_heads = num_attention_heads
|
| 55 |
+
self.num_channels = num_channels
|
| 56 |
+
self.patch_size = patch_size
|
| 57 |
+
self.image_size = image_size
|
| 58 |
+
self.attention_dropout = attention_dropout
|
| 59 |
+
self.rms_norm_eps = rms_norm_eps
|
| 60 |
+
|
| 61 |
+
self.projection_dropout = projection_dropout
|
| 62 |
+
self.qkv_bias = qkv_bias
|
| 63 |
+
self.use_bias = use_bias
|
configuration_ovis.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import List, Dict, Union, Optional
|
| 3 |
+
|
| 4 |
+
from transformers import PretrainedConfig, AutoConfig, AutoModel
|
| 5 |
+
from .configuration_aimv2 import AIMv2Config
|
| 6 |
+
from .modeling_aimv2 import AIMv2Model
|
| 7 |
+
|
| 8 |
+
IGNORE_ID = -100
|
| 9 |
+
IMAGE_TOKEN_ID = -200
|
| 10 |
+
IMAGE_TOKEN = "<image>"
|
| 11 |
+
IMAGE_ATOM_ID = -300
|
| 12 |
+
IMAGE_INDICATOR_IDS = [-301, -302, -303, -304, -305]
|
| 13 |
+
|
| 14 |
+
AutoConfig.register("aimv2", AIMv2Config)
|
| 15 |
+
AutoModel.register(AIMv2Config, AIMv2Model)
|
| 16 |
+
|
| 17 |
+
# ----------------------------------------------------------------------
|
| 18 |
+
# Visual Tokenizer Configuration
|
| 19 |
+
# ----------------------------------------------------------------------
|
| 20 |
+
class BaseVisualTokenizerConfig(PretrainedConfig):
|
| 21 |
+
def __init__(
|
| 22 |
+
self,
|
| 23 |
+
vocab_size=16384,
|
| 24 |
+
tokenize_function="softmax",
|
| 25 |
+
tau=1.0,
|
| 26 |
+
depths=None,
|
| 27 |
+
drop_cls_token=False,
|
| 28 |
+
backbone_config: Optional[Union[PretrainedConfig, dict]] = None,
|
| 29 |
+
hidden_stride: int = 1,
|
| 30 |
+
**kwargs
|
| 31 |
+
):
|
| 32 |
+
super().__init__(**kwargs)
|
| 33 |
+
self.vocab_size = vocab_size
|
| 34 |
+
self.tokenize_function = tokenize_function
|
| 35 |
+
self.tau = tau
|
| 36 |
+
if isinstance(depths, str):
|
| 37 |
+
depths = [int(x) for x in depths.split('|')]
|
| 38 |
+
self.depths = depths
|
| 39 |
+
self.backbone_kwargs = {}
|
| 40 |
+
self.drop_cls_token = drop_cls_token
|
| 41 |
+
if backbone_config is not None:
|
| 42 |
+
assert isinstance(backbone_config, (PretrainedConfig, dict)), \
|
| 43 |
+
f"expect `backbone_config` to be instance of PretrainedConfig or dict, but got {type(backbone_config)} type"
|
| 44 |
+
if not isinstance(backbone_config, PretrainedConfig):
|
| 45 |
+
model_type = backbone_config['model_type']
|
| 46 |
+
backbone_config.pop('model_type')
|
| 47 |
+
backbone_config = AutoConfig.for_model(model_type, **backbone_config)
|
| 48 |
+
self.backbone_config = backbone_config
|
| 49 |
+
self.hidden_stride = hidden_stride
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class Aimv2VisualTokenizerConfig(BaseVisualTokenizerConfig):
|
| 53 |
+
model_type = "aimv2_visual_tokenizer"
|
| 54 |
+
|
| 55 |
+
def __init__(self, **kwargs):
|
| 56 |
+
super().__init__(**kwargs)
|
| 57 |
+
if self.drop_cls_token:
|
| 58 |
+
self.drop_cls_token = False
|
| 59 |
+
if self.depths:
|
| 60 |
+
assert len(self.depths) == 1
|
| 61 |
+
self.backbone_kwargs['num_hidden_layers'] = self.depths[0]
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
AutoConfig.register("aimv2_visual_tokenizer", Aimv2VisualTokenizerConfig)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
# ----------------------------------------------------------------------
|
| 68 |
+
# Ovis Configuration
|
| 69 |
+
# ----------------------------------------------------------------------
|
| 70 |
+
class OvisConfig(PretrainedConfig):
|
| 71 |
+
model_type = "ovis"
|
| 72 |
+
|
| 73 |
+
def __init__(
|
| 74 |
+
self,
|
| 75 |
+
llm_config: Optional[Union[PretrainedConfig, dict]] = None,
|
| 76 |
+
visual_tokenizer_config: Optional[Union[PretrainedConfig, dict]] = None,
|
| 77 |
+
multimodal_max_length=8192,
|
| 78 |
+
hidden_size=None,
|
| 79 |
+
conversation_formatter_class=None,
|
| 80 |
+
llm_attn_implementation=None,
|
| 81 |
+
disable_tie_weight=False,
|
| 82 |
+
**kwargs
|
| 83 |
+
):
|
| 84 |
+
super().__init__(**kwargs)
|
| 85 |
+
if llm_config is not None:
|
| 86 |
+
assert isinstance(llm_config, (PretrainedConfig, dict)), \
|
| 87 |
+
f"expect `llm_config` to be instance of PretrainedConfig or dict, but got {type(llm_config)} type"
|
| 88 |
+
if not isinstance(llm_config, PretrainedConfig):
|
| 89 |
+
model_type = llm_config['model_type']
|
| 90 |
+
llm_config.pop('model_type')
|
| 91 |
+
llm_config = AutoConfig.for_model(model_type, **llm_config)
|
| 92 |
+
self.llm_config = llm_config
|
| 93 |
+
if visual_tokenizer_config is not None:
|
| 94 |
+
assert isinstance(visual_tokenizer_config, (PretrainedConfig, dict)), \
|
| 95 |
+
f"expect `visual_tokenizer_config` to be instance of PretrainedConfig or dict, but got {type(visual_tokenizer_config)} type"
|
| 96 |
+
if not isinstance(visual_tokenizer_config, PretrainedConfig):
|
| 97 |
+
model_type = visual_tokenizer_config['model_type']
|
| 98 |
+
visual_tokenizer_config.pop('model_type')
|
| 99 |
+
visual_tokenizer_config = AutoConfig.for_model(model_type, **visual_tokenizer_config)
|
| 100 |
+
self.visual_tokenizer_config = visual_tokenizer_config
|
| 101 |
+
self.multimodal_max_length = multimodal_max_length
|
| 102 |
+
self.hidden_size = hidden_size
|
| 103 |
+
self.conversation_formatter_class = conversation_formatter_class
|
| 104 |
+
self.llm_attn_implementation = llm_attn_implementation
|
| 105 |
+
self.disable_tie_weight = disable_tie_weight
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
# ----------------------------------------------------------------------
|
| 109 |
+
# Conversation Formatter
|
| 110 |
+
# ----------------------------------------------------------------------
|
| 111 |
+
class ConversationFormatter(ABC):
|
| 112 |
+
support_tokenizer_types = None
|
| 113 |
+
|
| 114 |
+
def __init__(self, tokenizer):
|
| 115 |
+
tokenizer_type = type(tokenizer).__name__
|
| 116 |
+
assert tokenizer_type in self.support_tokenizer_types, \
|
| 117 |
+
f'Invalid tokenizer type, expected one from `{self.support_tokenizer_types}`, but got `{tokenizer_type}`'
|
| 118 |
+
self.tokenizer = tokenizer
|
| 119 |
+
self.image_token = IMAGE_TOKEN
|
| 120 |
+
self.image_token_id = IMAGE_TOKEN_ID
|
| 121 |
+
self.ignore_id = IGNORE_ID
|
| 122 |
+
|
| 123 |
+
def _tokenize_with_image_symbol(self, text):
|
| 124 |
+
text_chunks = [self.tokenizer(chunk, add_special_tokens=False).input_ids for chunk in
|
| 125 |
+
text.split(self.image_token)]
|
| 126 |
+
token_ids = []
|
| 127 |
+
num_chuck = len(text_chunks)
|
| 128 |
+
for i, chunk in enumerate(text_chunks):
|
| 129 |
+
token_ids.extend(chunk)
|
| 130 |
+
if i < num_chuck - 1:
|
| 131 |
+
token_ids.append(self.image_token_id)
|
| 132 |
+
return token_ids
|
| 133 |
+
|
| 134 |
+
@abstractmethod
|
| 135 |
+
def format(self, conversations: List[Dict], generation_preface=None):
|
| 136 |
+
pass
|
| 137 |
+
|
| 138 |
+
@abstractmethod
|
| 139 |
+
def format_query(self, query, generation_preface=""):
|
| 140 |
+
pass
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
class QwenConversationFormatter(ConversationFormatter):
|
| 144 |
+
support_tokenizer_types = ['QWenTokenizer', 'Qwen2TokenizerFast']
|
| 145 |
+
|
| 146 |
+
def __init__(self, tokenizer):
|
| 147 |
+
super().__init__(tokenizer)
|
| 148 |
+
self.from2role = {
|
| 149 |
+
"system": "<|im_start|>system\n",
|
| 150 |
+
"human": "<|im_start|>user\n",
|
| 151 |
+
"gpt": "<|im_start|>assistant\n",
|
| 152 |
+
}
|
| 153 |
+
self.gpt_token_num = None
|
| 154 |
+
self.im_end = "<|im_end|>\n"
|
| 155 |
+
self.default_system_prompt = "You are a helpful assistant."
|
| 156 |
+
|
| 157 |
+
def format(self, conversations: List[Dict], generation_preface=None):
|
| 158 |
+
if self.gpt_token_num is None:
|
| 159 |
+
self.gpt_token_num = len(self.tokenizer(self.from2role["gpt"], add_special_tokens=False).input_ids)
|
| 160 |
+
|
| 161 |
+
if conversations[0]["from"] != "system":
|
| 162 |
+
conversations.insert(0, {
|
| 163 |
+
"from": "system",
|
| 164 |
+
"value": self.default_system_prompt
|
| 165 |
+
})
|
| 166 |
+
|
| 167 |
+
if generation_preface is not None:
|
| 168 |
+
conversations.append({
|
| 169 |
+
"from": "gpt",
|
| 170 |
+
"value": generation_preface
|
| 171 |
+
})
|
| 172 |
+
|
| 173 |
+
prompt = ""
|
| 174 |
+
input_ids = []
|
| 175 |
+
labels = []
|
| 176 |
+
num_conversation = len(conversations)
|
| 177 |
+
for i, conversation in enumerate(conversations):
|
| 178 |
+
frm = conversation["from"]
|
| 179 |
+
role = self.from2role[frm]
|
| 180 |
+
message = conversation["value"]
|
| 181 |
+
text = role + message
|
| 182 |
+
if i < num_conversation - 1 or generation_preface is None:
|
| 183 |
+
text += self.im_end
|
| 184 |
+
prompt += text
|
| 185 |
+
token_ids = self._tokenize_with_image_symbol(text)
|
| 186 |
+
input_ids.extend(token_ids)
|
| 187 |
+
label_ids = [self.ignore_id] * len(token_ids)
|
| 188 |
+
if frm == "gpt" and generation_preface is None:
|
| 189 |
+
# learning `\n` following `im_end` is meaningless, so the last `\n` token is ignored in label
|
| 190 |
+
label_ids[self.gpt_token_num:-1] = token_ids[self.gpt_token_num:-1]
|
| 191 |
+
labels.extend(label_ids)
|
| 192 |
+
|
| 193 |
+
assert self._tokenize_with_image_symbol(prompt) == input_ids
|
| 194 |
+
assert len(input_ids) == len(labels)
|
| 195 |
+
|
| 196 |
+
return prompt, input_ids, labels
|
| 197 |
+
|
| 198 |
+
def format_query(self, query, generation_preface=""):
|
| 199 |
+
prompt, input_ids, _ = self.format([{
|
| 200 |
+
"from": "human",
|
| 201 |
+
"value": query
|
| 202 |
+
}], generation_preface=generation_preface)
|
| 203 |
+
|
| 204 |
+
return prompt, input_ids
|
generation_config.json
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"multimodal_max_length": 32768,
|
| 9 |
+
"pad_token_id": 151643,
|
| 10 |
+
"repetition_penalty": 1.1,
|
| 11 |
+
"temperature": 0.7,
|
| 12 |
+
"top_k": 20,
|
| 13 |
+
"top_p": 0.8,
|
| 14 |
+
"transformers_version": "4.46.2"
|
| 15 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a25670ed919d7cc9fad1fa4a359b3da5a0b744eab448a498d6c23cdc8b9edc2
|
| 3 |
+
size 2534893180
|
modeling_aimv2.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# adapted from https://huggingface.co/apple/aimv2-huge-patch14-448 (modification: add gradient checkpoint support)
|
| 2 |
+
from typing import Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from .configuration_aimv2 import AIMv2Config
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
from transformers.modeling_outputs import BaseModelOutputWithNoAttention
|
| 9 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 10 |
+
|
| 11 |
+
__all__ = ["AIMv2Model"]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class RMSNorm(nn.Module):
|
| 15 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 18 |
+
self.eps = eps
|
| 19 |
+
|
| 20 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 21 |
+
output = self._norm(x.float()).type_as(x)
|
| 22 |
+
return output * self.weight
|
| 23 |
+
|
| 24 |
+
def extra_repr(self) -> str:
|
| 25 |
+
return f"{tuple(self.weight.shape)}, eps={self.eps}"
|
| 26 |
+
|
| 27 |
+
def _norm(self, x: torch.Tensor) -> torch.Tensor:
|
| 28 |
+
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class AIMv2SwiGLUFFN(nn.Module):
|
| 32 |
+
def __init__(self, config: AIMv2Config):
|
| 33 |
+
super().__init__()
|
| 34 |
+
hidden_features = config.intermediate_size
|
| 35 |
+
in_features = config.hidden_size
|
| 36 |
+
bias = config.use_bias
|
| 37 |
+
|
| 38 |
+
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
|
| 39 |
+
self.fc2 = nn.Linear(hidden_features, in_features, bias=bias)
|
| 40 |
+
self.fc3 = nn.Linear(in_features, hidden_features, bias=bias)
|
| 41 |
+
|
| 42 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 43 |
+
x = F.silu(self.fc1(x)) * self.fc3(x)
|
| 44 |
+
x = self.fc2(x)
|
| 45 |
+
return x
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class AIMv2PatchEmbed(nn.Module):
|
| 49 |
+
def __init__(self, config: AIMv2Config):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.proj = nn.Conv2d(
|
| 52 |
+
config.num_channels,
|
| 53 |
+
config.hidden_size,
|
| 54 |
+
kernel_size=(config.patch_size, config.patch_size),
|
| 55 |
+
stride=(config.patch_size, config.patch_size),
|
| 56 |
+
)
|
| 57 |
+
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 58 |
+
|
| 59 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 60 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 61 |
+
x = self.norm(x)
|
| 62 |
+
return x
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class AIMv2ViTPreprocessor(nn.Module):
|
| 66 |
+
def __init__(self, config: AIMv2Config):
|
| 67 |
+
super().__init__()
|
| 68 |
+
num_patches = (config.image_size // config.patch_size) ** 2
|
| 69 |
+
|
| 70 |
+
self.patchifier = AIMv2PatchEmbed(config)
|
| 71 |
+
self.pos_embed = nn.Parameter(torch.zeros((1, num_patches, config.hidden_size)))
|
| 72 |
+
|
| 73 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 74 |
+
tokens = self.patchifier(x)
|
| 75 |
+
_, N, _ = tokens.shape
|
| 76 |
+
pos_embed = self.pos_embed.to(tokens.device)
|
| 77 |
+
tokens = tokens + pos_embed[:, :N]
|
| 78 |
+
return tokens
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class AIMv2Attention(nn.Module):
|
| 82 |
+
def __init__(self, config: AIMv2Config):
|
| 83 |
+
super().__init__()
|
| 84 |
+
dim = config.hidden_size
|
| 85 |
+
|
| 86 |
+
self.num_heads = config.num_attention_heads
|
| 87 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=config.qkv_bias)
|
| 88 |
+
self.attn_drop = nn.Dropout(config.attention_dropout)
|
| 89 |
+
self.proj = nn.Linear(dim, dim, bias=config.use_bias)
|
| 90 |
+
self.proj_drop = nn.Dropout(config.projection_dropout)
|
| 91 |
+
|
| 92 |
+
def forward(
|
| 93 |
+
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
| 94 |
+
) -> torch.Tensor:
|
| 95 |
+
B, N, C = x.shape
|
| 96 |
+
qkv = (
|
| 97 |
+
self.qkv(x)
|
| 98 |
+
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
| 99 |
+
.permute(2, 0, 3, 1, 4)
|
| 100 |
+
)
|
| 101 |
+
q, k, v = qkv.unbind(0)
|
| 102 |
+
|
| 103 |
+
x = F.scaled_dot_product_attention(q, k, v, attn_mask=mask)
|
| 104 |
+
x = x.transpose(1, 2).contiguous().reshape(B, N, C)
|
| 105 |
+
x = self.proj(x)
|
| 106 |
+
x = self.proj_drop(x)
|
| 107 |
+
return x
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class AIMv2Block(nn.Module):
|
| 111 |
+
def __init__(self, config: AIMv2Config):
|
| 112 |
+
super().__init__()
|
| 113 |
+
self.attn = AIMv2Attention(config)
|
| 114 |
+
self.norm_1 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 115 |
+
self.mlp = AIMv2SwiGLUFFN(config)
|
| 116 |
+
self.norm_2 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 117 |
+
|
| 118 |
+
def forward(
|
| 119 |
+
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
| 120 |
+
) -> torch.Tensor:
|
| 121 |
+
x = x + self.attn(self.norm_1(x), mask)
|
| 122 |
+
x = x + self.mlp(self.norm_2(x))
|
| 123 |
+
return x
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
class AIMv2Transformer(nn.Module):
|
| 127 |
+
def __init__(self, config: AIMv2Config):
|
| 128 |
+
super().__init__()
|
| 129 |
+
self.blocks = nn.ModuleList(
|
| 130 |
+
[AIMv2Block(config) for _ in range(config.num_hidden_layers)]
|
| 131 |
+
)
|
| 132 |
+
self.post_trunk_norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 133 |
+
self.gradient_checkpointing = False
|
| 134 |
+
|
| 135 |
+
def forward(
|
| 136 |
+
self,
|
| 137 |
+
tokens: torch.Tensor,
|
| 138 |
+
mask: Optional[torch.Tensor] = None,
|
| 139 |
+
output_hidden_states: bool = False,
|
| 140 |
+
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor, ...]]]:
|
| 141 |
+
hidden_states = () if output_hidden_states else None
|
| 142 |
+
for block in self.blocks:
|
| 143 |
+
if self.gradient_checkpointing and self.training:
|
| 144 |
+
tokens = self._gradient_checkpointing_func(block.__call__, tokens, mask)
|
| 145 |
+
else:
|
| 146 |
+
tokens = block(tokens, mask)
|
| 147 |
+
if output_hidden_states:
|
| 148 |
+
hidden_states += (tokens,)
|
| 149 |
+
tokens = self.post_trunk_norm(tokens)
|
| 150 |
+
return tokens, hidden_states
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class AIMv2PretrainedModel(PreTrainedModel):
|
| 154 |
+
config_class = AIMv2Config
|
| 155 |
+
base_model_prefix = "aimv2"
|
| 156 |
+
supports_gradient_checkpointing = True
|
| 157 |
+
main_input_name = "pixel_values"
|
| 158 |
+
_no_split_modules = ["AIMv2ViTPreprocessor", "AIMv2Block"]
|
| 159 |
+
_supports_sdpa = True
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class AIMv2Model(AIMv2PretrainedModel):
|
| 163 |
+
def __init__(self, config: AIMv2Config):
|
| 164 |
+
super().__init__(config)
|
| 165 |
+
self.preprocessor = AIMv2ViTPreprocessor(config)
|
| 166 |
+
self.trunk = AIMv2Transformer(config)
|
| 167 |
+
|
| 168 |
+
def forward(
|
| 169 |
+
self,
|
| 170 |
+
pixel_values: torch.Tensor,
|
| 171 |
+
mask: Optional[torch.Tensor] = None,
|
| 172 |
+
output_hidden_states: Optional[bool] = None,
|
| 173 |
+
return_dict: Optional[bool] = None,
|
| 174 |
+
) -> Union[
|
| 175 |
+
Tuple[torch.Tensor],
|
| 176 |
+
Tuple[torch.Tensor, Tuple[torch.Tensor, ...]],
|
| 177 |
+
BaseModelOutputWithNoAttention,
|
| 178 |
+
]:
|
| 179 |
+
if output_hidden_states is None:
|
| 180 |
+
output_hidden_states = self.config.output_hidden_states
|
| 181 |
+
if return_dict is None:
|
| 182 |
+
return_dict = self.config.use_return_dict
|
| 183 |
+
|
| 184 |
+
x = self.preprocessor(pixel_values)
|
| 185 |
+
x, hidden_states = self.trunk(
|
| 186 |
+
x, mask, output_hidden_states=output_hidden_states
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
if not return_dict:
|
| 190 |
+
res = (x,)
|
| 191 |
+
res += (hidden_states,) if output_hidden_states else ()
|
| 192 |
+
return res
|
| 193 |
+
|
| 194 |
+
return BaseModelOutputWithNoAttention(
|
| 195 |
+
last_hidden_state=x,
|
| 196 |
+
hidden_states=hidden_states,
|
| 197 |
+
)
|
| 198 |
+
|
modeling_ovis.py
ADDED
|
@@ -0,0 +1,590 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (C) 2025 AIDC-AI
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 7 |
+
#
|
| 8 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 9 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 10 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 11 |
+
#
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import logging
|
| 16 |
+
import os
|
| 17 |
+
import importlib.metadata
|
| 18 |
+
|
| 19 |
+
from packaging import version
|
| 20 |
+
from importlib import import_module
|
| 21 |
+
from typing import List, Callable, Union, Optional, Dict
|
| 22 |
+
|
| 23 |
+
import PIL.Image
|
| 24 |
+
import torch
|
| 25 |
+
from torch import Tensor
|
| 26 |
+
from torch.nn import init
|
| 27 |
+
from torch.nn.functional import softmax, gumbel_softmax, pad
|
| 28 |
+
from transformers.utils import is_flash_attn_2_available
|
| 29 |
+
from transformers import PreTrainedModel, AutoModel, AutoTokenizer, AutoModelForCausalLM, AutoImageProcessor
|
| 30 |
+
from transformers.generation.utils import GenerateOutput
|
| 31 |
+
|
| 32 |
+
from .configuration_ovis import BaseVisualTokenizerConfig, Aimv2VisualTokenizerConfig
|
| 33 |
+
from .configuration_ovis import OvisConfig, ConversationFormatter
|
| 34 |
+
from .configuration_ovis import IGNORE_ID, IMAGE_ATOM_ID, IMAGE_INDICATOR_IDS, IMAGE_TOKEN_ID
|
| 35 |
+
|
| 36 |
+
# ----------------------------------------------------------------------
|
| 37 |
+
# Visual Tokenizer
|
| 38 |
+
# ----------------------------------------------------------------------
|
| 39 |
+
class BaseVisualTokenizer(PreTrainedModel):
|
| 40 |
+
base_model_prefix = "backbone"
|
| 41 |
+
main_input_name = None
|
| 42 |
+
_image_processor_class = None
|
| 43 |
+
_image_processor_kwargs = {}
|
| 44 |
+
_backbone_class = None
|
| 45 |
+
_backbone_name_or_path = None
|
| 46 |
+
|
| 47 |
+
def __init__(self, config: BaseVisualTokenizerConfig, *inputs, **kwargs):
|
| 48 |
+
super().__init__(config, *inputs, **kwargs)
|
| 49 |
+
self.image_processor = AutoImageProcessor.from_pretrained(kwargs['image_processor_name_or_path'])
|
| 50 |
+
self.backbone = AutoModel.from_config(self.config.backbone_config)
|
| 51 |
+
head_dim = self.config.vocab_size - len(IMAGE_INDICATOR_IDS) # reserved tokens for IMAGE_INDICATORS
|
| 52 |
+
self.head = torch.nn.Sequential(
|
| 53 |
+
torch.nn.Linear(
|
| 54 |
+
self.backbone.config.hidden_size * self.config.hidden_stride * self.config.hidden_stride, head_dim,
|
| 55 |
+
bias=False
|
| 56 |
+
),
|
| 57 |
+
torch.nn.LayerNorm(head_dim)
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
assert all((self.image_processor.do_resize,
|
| 61 |
+
not getattr(self.image_processor, 'do_center_crop', False),
|
| 62 |
+
self.image_processor.do_rescale,
|
| 63 |
+
self.image_processor.do_normalize
|
| 64 |
+
)), f"image_processor `{self.image_processor}` is not supported currently"
|
| 65 |
+
|
| 66 |
+
def get_backbone(self):
|
| 67 |
+
return self.backbone
|
| 68 |
+
|
| 69 |
+
def get_image_processor(self):
|
| 70 |
+
return self.image_processor
|
| 71 |
+
|
| 72 |
+
def mock_input(self):
|
| 73 |
+
height, width = self.get_image_size()
|
| 74 |
+
return torch.zeros(1, 3, height, width), self.construct_image_placeholders((1, 1))
|
| 75 |
+
|
| 76 |
+
def get_head(self):
|
| 77 |
+
return self.head
|
| 78 |
+
|
| 79 |
+
def get_image_size(self):
|
| 80 |
+
raise NotImplementedError
|
| 81 |
+
|
| 82 |
+
@staticmethod
|
| 83 |
+
def construct_image_placeholders(grid):
|
| 84 |
+
image_placeholders = [IMAGE_INDICATOR_IDS[0], IMAGE_ATOM_ID, IMAGE_INDICATOR_IDS[1]]
|
| 85 |
+
if grid[0] * grid[1] > 1:
|
| 86 |
+
for r in range(grid[0]):
|
| 87 |
+
for c in range(grid[1]):
|
| 88 |
+
image_placeholders.append(IMAGE_ATOM_ID)
|
| 89 |
+
if c < grid[1] - 1:
|
| 90 |
+
image_placeholders.append(IMAGE_INDICATOR_IDS[2])
|
| 91 |
+
if r < grid[0] - 1:
|
| 92 |
+
image_placeholders.append(IMAGE_INDICATOR_IDS[3])
|
| 93 |
+
image_placeholders.append(IMAGE_INDICATOR_IDS[4])
|
| 94 |
+
return image_placeholders
|
| 95 |
+
|
| 96 |
+
def preprocess_image(self, image: PIL.Image.Image, max_partition=9, covering_threshold=0.9, convert_to_rgb=True):
|
| 97 |
+
def _preprocess(img: PIL.Image.Image, side):
|
| 98 |
+
# first resize and preprocess
|
| 99 |
+
w, h = img.size
|
| 100 |
+
if w == h:
|
| 101 |
+
new_width = new_height = side
|
| 102 |
+
elif w > h:
|
| 103 |
+
new_width = side
|
| 104 |
+
new_height = int(h / w * new_width)
|
| 105 |
+
else:
|
| 106 |
+
new_height = side
|
| 107 |
+
new_width = int(w / h * new_height)
|
| 108 |
+
new_size = dict(height=new_height, width=new_width)
|
| 109 |
+
pixel_values = self.image_processor.preprocess(img, size=new_size, return_tensors='pt')['pixel_values']
|
| 110 |
+
|
| 111 |
+
# then pad to square
|
| 112 |
+
square_values = torch.zeros([1, 3, side, side], dtype=pixel_values.dtype, device=pixel_values.device)
|
| 113 |
+
new_height, new_width = pixel_values.shape[2:]
|
| 114 |
+
if new_height == new_width:
|
| 115 |
+
square_values[:, :, :, :] = pixel_values
|
| 116 |
+
elif new_height > new_width:
|
| 117 |
+
from_index = (side - new_width) // 2
|
| 118 |
+
square_values[:, :, :, from_index:from_index + new_width] = pixel_values
|
| 119 |
+
else:
|
| 120 |
+
from_index = (side - new_height) // 2
|
| 121 |
+
square_values[:, :, from_index:from_index + new_height, :] = pixel_values
|
| 122 |
+
|
| 123 |
+
return square_values
|
| 124 |
+
|
| 125 |
+
def _partition(img, grid):
|
| 126 |
+
w, h = img.size
|
| 127 |
+
row_height = h // grid[0]
|
| 128 |
+
col_width = w // grid[1]
|
| 129 |
+
|
| 130 |
+
partition = []
|
| 131 |
+
for row in range(grid[0]):
|
| 132 |
+
for col in range(grid[1]):
|
| 133 |
+
left = col * col_width
|
| 134 |
+
upper = row * row_height
|
| 135 |
+
right = w if col == grid[1] - 1 else (col + 1) * col_width
|
| 136 |
+
lower = h if row == grid[0] - 1 else (row + 1) * row_height
|
| 137 |
+
partition.append((left, upper, right, lower))
|
| 138 |
+
|
| 139 |
+
return partition
|
| 140 |
+
|
| 141 |
+
def _covering_area(left, upper, right, lower, side):
|
| 142 |
+
w = right - left
|
| 143 |
+
h = lower - upper
|
| 144 |
+
w, h = max(w, h), min(w, h)
|
| 145 |
+
if w > side:
|
| 146 |
+
h = h / w * side
|
| 147 |
+
w = side
|
| 148 |
+
return w * h
|
| 149 |
+
|
| 150 |
+
def _get_best_grid(img, side):
|
| 151 |
+
img_area = img.size[0] * img.size[1]
|
| 152 |
+
|
| 153 |
+
candidate_grids = []
|
| 154 |
+
for i in range(1, max_partition + 1):
|
| 155 |
+
for j in range(1, max_partition + 1):
|
| 156 |
+
if i * j <= max_partition:
|
| 157 |
+
candidate_grids.append((i, j))
|
| 158 |
+
|
| 159 |
+
all_grids = []
|
| 160 |
+
good_grids = []
|
| 161 |
+
for grid in candidate_grids:
|
| 162 |
+
partition = _partition(img, grid)
|
| 163 |
+
covering_ratio = sum([_covering_area(*p, side) for p in partition]) / img_area
|
| 164 |
+
assert covering_ratio <= 1.0
|
| 165 |
+
all_grids.append((grid, covering_ratio))
|
| 166 |
+
if covering_ratio > covering_threshold:
|
| 167 |
+
good_grids.append((grid, covering_ratio))
|
| 168 |
+
|
| 169 |
+
if len(good_grids) > 0:
|
| 170 |
+
# pick the good partition with minimum #sub_images and break the tie using covering_ratio
|
| 171 |
+
return sorted(good_grids, key=lambda x: (x[0][0] * x[0][1], -x[1]))[0][0]
|
| 172 |
+
else:
|
| 173 |
+
# pick the partition with maximum covering_ratio and break the tie using #sub_images
|
| 174 |
+
return sorted(all_grids, key=lambda x: (-x[1], x[0][0] * x[0][1]))[0][0]
|
| 175 |
+
|
| 176 |
+
if convert_to_rgb and image.mode != 'RGB':
|
| 177 |
+
image = image.convert('RGB')
|
| 178 |
+
|
| 179 |
+
sides = self.get_image_size()
|
| 180 |
+
if sides[0] != sides[1]:
|
| 181 |
+
raise ValueError('get_image_size() returns non-square size')
|
| 182 |
+
side = sides[0]
|
| 183 |
+
grid = _get_best_grid(image, side)
|
| 184 |
+
partition = _partition(image, grid)
|
| 185 |
+
crops = [image.crop(p) for p in partition]
|
| 186 |
+
if len(crops) > 1:
|
| 187 |
+
crops.insert(0, image)
|
| 188 |
+
pixel_values = torch.cat([_preprocess(crop, side) for crop in crops], dim=0)
|
| 189 |
+
image_placeholders = self.construct_image_placeholders(grid)
|
| 190 |
+
return pixel_values, image_placeholders
|
| 191 |
+
|
| 192 |
+
def tokenize(self, logits):
|
| 193 |
+
def st_argmax(y_soft, dim): # straight-through softmax
|
| 194 |
+
index = y_soft.max(dim, keepdim=True)[1]
|
| 195 |
+
y_hard = torch.zeros_like(y_soft, memory_format=torch.legacy_contiguous_format).scatter_(dim, index, 1.0)
|
| 196 |
+
ret = y_hard - y_soft.detach() + y_soft
|
| 197 |
+
return ret
|
| 198 |
+
|
| 199 |
+
if self.config.tokenize_function == 'softmax':
|
| 200 |
+
tokens = softmax(logits, dim=-1)
|
| 201 |
+
elif self.config.tokenize_function == 'gumbel_argmax':
|
| 202 |
+
tokens = gumbel_softmax(logits, tau=self.config.tau, hard=True)
|
| 203 |
+
elif self.config.tokenize_function == 'st_argmax':
|
| 204 |
+
tokens = st_argmax(logits, dim=-1)
|
| 205 |
+
else:
|
| 206 |
+
raise ValueError(
|
| 207 |
+
f'Invalid `max_type`, expected softmax or gumbel_argmax or st_argmax, but got {self.config.tokenize_function}')
|
| 208 |
+
return tokens
|
| 209 |
+
|
| 210 |
+
def encode(self, pixel_values):
|
| 211 |
+
output = self.backbone(pixel_values, output_hidden_states=True, return_dict=True)
|
| 212 |
+
features = output.hidden_states[-1]
|
| 213 |
+
if self.config.drop_cls_token:
|
| 214 |
+
features = features[:, 1:, :]
|
| 215 |
+
|
| 216 |
+
# merge number of `hidden_stride * hidden_stride` hidden states together to reduce token sequence length
|
| 217 |
+
# e.g., for hidden_stride=2, this leads to a token length reduction: 1024 -> 256 for aimv2
|
| 218 |
+
if self.config.hidden_stride > 1:
|
| 219 |
+
n, l, d = features.shape # this `d` maybe different from the above `d
|
| 220 |
+
sqrt_l = int(l ** 0.5)
|
| 221 |
+
assert sqrt_l ** 2 == l, "The token sequence length should be a perfect square."
|
| 222 |
+
features = features.reshape(n, sqrt_l, sqrt_l, d)
|
| 223 |
+
pl = (self.config.hidden_stride - (sqrt_l % self.config.hidden_stride)) % self.config.hidden_stride
|
| 224 |
+
features = pad(features, (0, 0, 0, pl, 0, pl), "constant", 0)
|
| 225 |
+
sqrt_l += pl
|
| 226 |
+
features = features.reshape(n, sqrt_l // self.config.hidden_stride, self.config.hidden_stride,
|
| 227 |
+
sqrt_l // self.config.hidden_stride, self.config.hidden_stride, d)
|
| 228 |
+
features = features.permute(0, 1, 3, 2, 4, 5) # [n, sqrt_l/hs, sqrt_l/hs, hs, hs, d]
|
| 229 |
+
features = features.flatten(3) # [n, sqrt_l/hs, sqrt_l/hs, hs*hs*d]
|
| 230 |
+
features = features.reshape(
|
| 231 |
+
n, -1, self.config.hidden_stride * self.config.hidden_stride * d)
|
| 232 |
+
|
| 233 |
+
return features
|
| 234 |
+
|
| 235 |
+
def forward(self, pixel_values) -> torch.Tensor: # [BatchSize, ImageShape] -> [BatchSize, #Token, VocabSize]
|
| 236 |
+
features = self.encode(pixel_values)
|
| 237 |
+
logits = self.head(features)
|
| 238 |
+
tokens = self.tokenize(logits)
|
| 239 |
+
# tokens' shape is [BatchSize, #Token, VocabSize-5], so padding with [BatchSize, #Token, 5], after
|
| 240 |
+
# which, tokens' shape should become [BatchSize, #Token, VocabSize]
|
| 241 |
+
batch_size, token_len, _ = tokens.shape
|
| 242 |
+
padding_tensor = torch.zeros(size=(batch_size, token_len, len(IMAGE_INDICATOR_IDS)),
|
| 243 |
+
dtype=tokens.dtype,
|
| 244 |
+
device=tokens.device,
|
| 245 |
+
layout=tokens.layout,
|
| 246 |
+
requires_grad=False)
|
| 247 |
+
tokens = torch.cat((tokens, padding_tensor), dim=2)
|
| 248 |
+
return tokens
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
class Aimv2VisualTokenizer(BaseVisualTokenizer):
|
| 252 |
+
config_class = Aimv2VisualTokenizerConfig
|
| 253 |
+
supports_gradient_checkpointing = True
|
| 254 |
+
_no_split_modules = ["AIMv2ViTPreprocessor", "AIMv2Block"]
|
| 255 |
+
_image_processor_kwargs = dict(do_center_crop=False)
|
| 256 |
+
|
| 257 |
+
def get_image_size(self):
|
| 258 |
+
height = self.image_processor.crop_size["height"]
|
| 259 |
+
width = self.image_processor.crop_size["width"]
|
| 260 |
+
return height, width
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
AutoModel.register(Aimv2VisualTokenizerConfig, Aimv2VisualTokenizer)
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
# ----------------------------------------------------------------------
|
| 267 |
+
# Ovis
|
| 268 |
+
# ----------------------------------------------------------------------
|
| 269 |
+
class VisualEmbedding(torch.nn.Embedding):
|
| 270 |
+
def forward(self, visual_tokens: Tensor) -> Tensor:
|
| 271 |
+
if visual_tokens.dtype in [torch.int8, torch.int16, torch.int32, torch.int64, torch.long]:
|
| 272 |
+
return super().forward(visual_tokens)
|
| 273 |
+
return torch.matmul(visual_tokens, self.weight)
|
| 274 |
+
|
| 275 |
+
def reset_parameters(self, mean=0., std=1.) -> None:
|
| 276 |
+
init.normal_(self.weight, mean=mean, std=std)
|
| 277 |
+
self._fill_padding_idx_with_zero()
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class OvisPreTrainedModel(PreTrainedModel):
|
| 281 |
+
config_class = OvisConfig
|
| 282 |
+
base_model_prefix = "ovis"
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
class Ovis(OvisPreTrainedModel):
|
| 286 |
+
|
| 287 |
+
def __init__(self, config: OvisConfig, *inputs, **kwargs):
|
| 288 |
+
super().__init__(config, *inputs, **kwargs)
|
| 289 |
+
attn_kwargs = dict()
|
| 290 |
+
if self.config.llm_attn_implementation:
|
| 291 |
+
if self.config.llm_attn_implementation == "flash_attention_2":
|
| 292 |
+
assert (is_flash_attn_2_available() and
|
| 293 |
+
version.parse(importlib.metadata.version("flash_attn")) >= version.parse("2.6.3")), \
|
| 294 |
+
"Using `flash_attention_2` requires having `flash_attn>=2.6.3` installed."
|
| 295 |
+
attn_kwargs["attn_implementation"] = self.config.llm_attn_implementation
|
| 296 |
+
self.llm = AutoModelForCausalLM.from_config(self.config.llm_config, **attn_kwargs)
|
| 297 |
+
assert self.config.hidden_size == self.llm.config.hidden_size, "hidden size mismatch"
|
| 298 |
+
self.text_tokenizer = AutoTokenizer.from_pretrained(self.config.name_or_path)
|
| 299 |
+
self.visual_tokenizer = AutoModel.from_config(self.config.visual_tokenizer_config,
|
| 300 |
+
image_processor_name_or_path=self.config.name_or_path)
|
| 301 |
+
self.vte = VisualEmbedding(
|
| 302 |
+
self.config.visual_tokenizer_config.vocab_size,
|
| 303 |
+
self.config.hidden_size,
|
| 304 |
+
device=self.visual_tokenizer.device,
|
| 305 |
+
dtype=self.visual_tokenizer.dtype
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
def _merge_modules(modules_list: tuple):
|
| 309 |
+
merged_modules = []
|
| 310 |
+
for modules in modules_list:
|
| 311 |
+
merged_modules.extend(modules if modules else [])
|
| 312 |
+
return merged_modules
|
| 313 |
+
|
| 314 |
+
self._no_split_modules = _merge_modules((self.llm._no_split_modules, self.visual_tokenizer._no_split_modules))
|
| 315 |
+
self._skip_keys_device_placement = self.llm._skip_keys_device_placement
|
| 316 |
+
self._keep_in_fp32_modules = _merge_modules(
|
| 317 |
+
(self.llm._keep_in_fp32_modules, self.visual_tokenizer._keep_in_fp32_modules))
|
| 318 |
+
self.is_parallelizable = all((self.llm.is_parallelizable, self.visual_tokenizer.is_parallelizable))
|
| 319 |
+
self.supports_gradient_checkpointing = True
|
| 320 |
+
self._supports_flash_attn_2 = True
|
| 321 |
+
|
| 322 |
+
def get_text_tokenizer(self):
|
| 323 |
+
return self.text_tokenizer
|
| 324 |
+
|
| 325 |
+
def get_visual_tokenizer(self):
|
| 326 |
+
return self.visual_tokenizer
|
| 327 |
+
|
| 328 |
+
def tie_weights(self):
|
| 329 |
+
if not self.config.disable_tie_weight:
|
| 330 |
+
self.get_llm().tie_weights()
|
| 331 |
+
|
| 332 |
+
def get_llm(self):
|
| 333 |
+
return self.llm
|
| 334 |
+
|
| 335 |
+
def get_vte(self):
|
| 336 |
+
return self.vte
|
| 337 |
+
|
| 338 |
+
def get_wte(self):
|
| 339 |
+
return self.llm.get_input_embeddings()
|
| 340 |
+
|
| 341 |
+
def get_conversation_formatter(self) -> ConversationFormatter:
|
| 342 |
+
if getattr(self, 'conversation_formatter', None) is None:
|
| 343 |
+
self.conversation_formatter = getattr(import_module(".configuration_ovis", __package__),
|
| 344 |
+
self.config.conversation_formatter_class)(self.text_tokenizer)
|
| 345 |
+
return self.conversation_formatter
|
| 346 |
+
|
| 347 |
+
def forward(
|
| 348 |
+
self,
|
| 349 |
+
input_ids: torch.Tensor,
|
| 350 |
+
attention_mask: torch.Tensor,
|
| 351 |
+
labels: Optional[torch.Tensor],
|
| 352 |
+
pixel_values: List[Optional[torch.Tensor]],
|
| 353 |
+
**kwargs
|
| 354 |
+
):
|
| 355 |
+
# assert self.training, "`forward` can only be used in training. For inference, use `generate`."
|
| 356 |
+
_, inputs_embeds, labels, attention_mask = self.merge_multimodal(
|
| 357 |
+
text_input_ids=input_ids,
|
| 358 |
+
text_attention_masks=attention_mask,
|
| 359 |
+
text_labels=labels,
|
| 360 |
+
pixel_values=pixel_values
|
| 361 |
+
)
|
| 362 |
+
return self.llm(inputs_embeds=inputs_embeds, labels=labels, attention_mask=attention_mask, **kwargs)
|
| 363 |
+
|
| 364 |
+
def merge_multimodal(
|
| 365 |
+
self,
|
| 366 |
+
text_input_ids: torch.Tensor,
|
| 367 |
+
text_attention_masks: torch.Tensor,
|
| 368 |
+
text_labels: Optional[torch.Tensor],
|
| 369 |
+
pixel_values: List[Optional[torch.Tensor]],
|
| 370 |
+
left_padding: bool = False
|
| 371 |
+
):
|
| 372 |
+
input_device = text_input_ids.device
|
| 373 |
+
visual_vocab_szie = self.get_visual_tokenizer().config.vocab_size
|
| 374 |
+
visual_indicator_embeds = self.get_vte()(
|
| 375 |
+
torch.tensor(
|
| 376 |
+
list(range(visual_vocab_szie - 5, visual_vocab_szie)),
|
| 377 |
+
dtype=torch.long,
|
| 378 |
+
device=self.get_visual_tokenizer().device
|
| 379 |
+
)
|
| 380 |
+
).to(device=input_device)
|
| 381 |
+
|
| 382 |
+
if self.training:
|
| 383 |
+
# When training, to be compatible with deepspeed zero, each sample has to include pixel_value tensor.
|
| 384 |
+
# For text-only sample, one can simply use a full zero tensor as pixel_value, which will be ignored
|
| 385 |
+
# (see below in this function); so, the gradient will not be affected.
|
| 386 |
+
num_images = [x.shape[0] for x in pixel_values]
|
| 387 |
+
visual_tokens = self.visual_tokenizer(torch.cat([x for x in pixel_values], dim=0))
|
| 388 |
+
visual_embeds = torch.split(self.get_vte()(visual_tokens).to(dtype=self.dtype, device=input_device),
|
| 389 |
+
split_size_or_sections=num_images, dim=0)
|
| 390 |
+
visual_input_ids = torch.split(torch.argmax(visual_tokens, dim=-1).to(device=input_device),
|
| 391 |
+
split_size_or_sections=num_images, dim=0)
|
| 392 |
+
visual_labels = [torch.full(x.shape, IGNORE_ID, dtype=torch.long, device=input_device) for x in
|
| 393 |
+
visual_input_ids]
|
| 394 |
+
else:
|
| 395 |
+
# When inference, sample can include only text with `None` pixel_value
|
| 396 |
+
num_images = [x.shape[0] if x is not None else 0 for x in pixel_values]
|
| 397 |
+
if sum(num_images) > 0:
|
| 398 |
+
visual_tokens = self.visual_tokenizer(torch.cat([x for x in pixel_values if x is not None], dim=0))
|
| 399 |
+
visual_embeds = torch.split(self.get_vte()(visual_tokens).to(dtype=self.dtype, device=input_device),
|
| 400 |
+
split_size_or_sections=num_images, dim=0)
|
| 401 |
+
visual_input_ids = torch.split(torch.argmax(visual_tokens, dim=-1).to(device=input_device),
|
| 402 |
+
split_size_or_sections=num_images, dim=0)
|
| 403 |
+
visual_labels = [torch.full(x.shape, IGNORE_ID, dtype=torch.long, device=input_device) for x in
|
| 404 |
+
visual_input_ids]
|
| 405 |
+
else:
|
| 406 |
+
# just placeholders
|
| 407 |
+
visual_embeds = [None] * len(num_images)
|
| 408 |
+
visual_input_ids = [None] * len(num_images)
|
| 409 |
+
visual_labels = [None] * len(num_images)
|
| 410 |
+
# just placeholders
|
| 411 |
+
if text_labels is None:
|
| 412 |
+
text_labels = torch.full(text_input_ids.shape, IGNORE_ID, dtype=torch.long, device=input_device)
|
| 413 |
+
|
| 414 |
+
input_embeds = []
|
| 415 |
+
attention_masks = []
|
| 416 |
+
labels = []
|
| 417 |
+
for text_input_id, text_label, text_attention_mask, visual_embed, visual_input_id, visual_label in zip(
|
| 418 |
+
text_input_ids, text_labels, text_attention_masks, visual_embeds, visual_input_ids, visual_labels
|
| 419 |
+
):
|
| 420 |
+
placeholder_token_mask = torch.lt(text_input_id, 0)
|
| 421 |
+
text_embed = self.get_wte()(torch.masked_fill(text_input_id, placeholder_token_mask, 0))
|
| 422 |
+
for i, indicator_id in enumerate(IMAGE_INDICATOR_IDS):
|
| 423 |
+
text_embed[text_input_id == indicator_id] = visual_indicator_embeds[i]
|
| 424 |
+
image_atom_positions = torch.where(torch.eq(text_input_id, IMAGE_ATOM_ID))[0].tolist()
|
| 425 |
+
if len(image_atom_positions) > 0:
|
| 426 |
+
input_embed_parts = []
|
| 427 |
+
attention_mask_parts = []
|
| 428 |
+
label_parts = []
|
| 429 |
+
prev_image_atom_position = -1
|
| 430 |
+
for index, image_atom_position in enumerate(image_atom_positions):
|
| 431 |
+
input_embed_parts.append(
|
| 432 |
+
text_embed[prev_image_atom_position + 1:image_atom_position, :])
|
| 433 |
+
label_parts.append(
|
| 434 |
+
text_label[prev_image_atom_position + 1:image_atom_position])
|
| 435 |
+
attention_mask_parts.append(
|
| 436 |
+
text_attention_mask[prev_image_atom_position + 1:image_atom_position])
|
| 437 |
+
input_embed_parts.append(visual_embed[index])
|
| 438 |
+
attention_mask_parts.append(
|
| 439 |
+
torch.ones_like(visual_label[index], dtype=torch.bool))
|
| 440 |
+
label_parts.append(visual_label[index])
|
| 441 |
+
prev_image_atom_position = image_atom_position
|
| 442 |
+
if prev_image_atom_position + 1 < text_input_id.shape[0]:
|
| 443 |
+
input_embed_parts.append(
|
| 444 |
+
text_embed[prev_image_atom_position + 1:, :])
|
| 445 |
+
attention_mask_parts.append(
|
| 446 |
+
text_attention_mask[prev_image_atom_position + 1:])
|
| 447 |
+
label_parts.append(
|
| 448 |
+
text_label[prev_image_atom_position + 1:])
|
| 449 |
+
input_embed = torch.cat(input_embed_parts, dim=0)
|
| 450 |
+
attention_mask = torch.cat(attention_mask_parts, dim=0)
|
| 451 |
+
label = torch.cat(label_parts, dim=0)
|
| 452 |
+
else:
|
| 453 |
+
input_embed = text_embed
|
| 454 |
+
attention_mask = text_attention_mask
|
| 455 |
+
label = text_label
|
| 456 |
+
if self.training:
|
| 457 |
+
# Make visual_embed & visual_indicator_embeds involved in the backward graph,
|
| 458 |
+
# to be compatible with deepspeed zero and ddp.
|
| 459 |
+
input_embed += torch.sum(visual_embed * 0.0) + torch.sum(visual_indicator_embeds * 0.0)
|
| 460 |
+
input_embeds.append(input_embed)
|
| 461 |
+
attention_masks.append(attention_mask)
|
| 462 |
+
labels.append(label)
|
| 463 |
+
|
| 464 |
+
if self.training: # padding to self.config.multimodal_max_length for increased training speed
|
| 465 |
+
padding_size = max(0, self.config.multimodal_max_length - len(input_embeds[0]))
|
| 466 |
+
input_embeds[0] = torch.nn.ConstantPad2d((0, 0, 0, padding_size), 0.0)(input_embeds[0])
|
| 467 |
+
attention_masks[0] = torch.nn.ConstantPad1d((0, padding_size), False)(attention_masks[0])
|
| 468 |
+
labels[0] = torch.nn.ConstantPad1d((0, padding_size), IGNORE_ID)(labels[0])
|
| 469 |
+
batch_input_embeds = self.pad_truncate_sequence(input_embeds, batch_first=True, padding_value=0.0, left_padding=left_padding)
|
| 470 |
+
batch_attention_mask = self.pad_truncate_sequence(attention_masks, batch_first=True, padding_value=False, left_padding=left_padding)
|
| 471 |
+
batch_labels = self.pad_truncate_sequence(labels, batch_first=True, padding_value=IGNORE_ID, left_padding=left_padding)
|
| 472 |
+
|
| 473 |
+
return visual_input_ids, batch_input_embeds, batch_labels, batch_attention_mask
|
| 474 |
+
|
| 475 |
+
def pad_truncate_sequence(self, sequences: List[torch.Tensor], batch_first: bool = True, padding_value: float = 0.0, left_padding: bool = False) -> torch.Tensor:
|
| 476 |
+
if not left_padding:
|
| 477 |
+
pad_sequence = torch.nn.utils.rnn.pad_sequence(sequences, batch_first=batch_first, padding_value=padding_value)
|
| 478 |
+
return pad_sequence[:,:self.config.multimodal_max_length]
|
| 479 |
+
else:
|
| 480 |
+
pad_sequence = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in sequences],batch_first=True, padding_value=padding_value).flip(dims=[1])
|
| 481 |
+
return pad_sequence[:,-self.config.multimodal_max_length:]
|
| 482 |
+
|
| 483 |
+
def preprocess_inputs(
|
| 484 |
+
self,
|
| 485 |
+
text_or_conversations: Union[List[Dict], str],
|
| 486 |
+
images: Optional[List[PIL.Image.Image]],
|
| 487 |
+
max_partition=9,
|
| 488 |
+
generation_preface='',
|
| 489 |
+
return_labels=False,
|
| 490 |
+
propagate_exception=True,
|
| 491 |
+
frame_selector=None,
|
| 492 |
+
frame_selector_kwargs=None
|
| 493 |
+
):
|
| 494 |
+
# convert text to conversations
|
| 495 |
+
if isinstance(text_or_conversations, str):
|
| 496 |
+
conversations = [{
|
| 497 |
+
"from": "human",
|
| 498 |
+
"value": text_or_conversations
|
| 499 |
+
}]
|
| 500 |
+
elif isinstance(text_or_conversations, list):
|
| 501 |
+
conversations = text_or_conversations
|
| 502 |
+
else:
|
| 503 |
+
raise ValueError(f'Invalid type of `text_or_conversations`, expected `List[Dict]` or `str`,'
|
| 504 |
+
f' but got {type(text_or_conversations)}')
|
| 505 |
+
|
| 506 |
+
if frame_selector is not None:
|
| 507 |
+
frame_selector_kwargs = frame_selector_kwargs or {}
|
| 508 |
+
conversations, images = frame_selector(conversations=conversations, frames=images, **frame_selector_kwargs)
|
| 509 |
+
|
| 510 |
+
# format conversations
|
| 511 |
+
prompt, raw_input_ids, raw_labels = self.get_conversation_formatter().format(
|
| 512 |
+
conversations, generation_preface=generation_preface)
|
| 513 |
+
|
| 514 |
+
# place image placeholders
|
| 515 |
+
input_ids = []
|
| 516 |
+
labels = []
|
| 517 |
+
pixel_values = []
|
| 518 |
+
invalidate_label = False
|
| 519 |
+
image_token_indices = [i for i, v in enumerate(raw_input_ids) if v == IMAGE_TOKEN_ID]
|
| 520 |
+
last_image_token_index = -1
|
| 521 |
+
for i in range(len(image_token_indices)):
|
| 522 |
+
head = 0 if i == 0 else image_token_indices[i - 1] + 1
|
| 523 |
+
tail = image_token_indices[i]
|
| 524 |
+
last_image_token_index = tail
|
| 525 |
+
input_ids.extend(raw_input_ids[head:tail])
|
| 526 |
+
labels.extend(raw_labels[head:tail])
|
| 527 |
+
try:
|
| 528 |
+
image = images[i]
|
| 529 |
+
raw_pixel_values, image_placeholders = self.visual_tokenizer.preprocess_image(
|
| 530 |
+
image, max_partition=max_partition)
|
| 531 |
+
except Exception as e:
|
| 532 |
+
if propagate_exception:
|
| 533 |
+
raise e
|
| 534 |
+
logging.exception(e)
|
| 535 |
+
invalidate_label = True
|
| 536 |
+
raw_pixel_values, image_placeholders = self.visual_tokenizer.mock_input()
|
| 537 |
+
input_ids.extend(image_placeholders)
|
| 538 |
+
labels.extend([IGNORE_ID] * len(image_placeholders))
|
| 539 |
+
pixel_values.append(raw_pixel_values)
|
| 540 |
+
input_ids.extend(raw_input_ids[last_image_token_index + 1:])
|
| 541 |
+
labels.extend(raw_labels[last_image_token_index + 1:])
|
| 542 |
+
|
| 543 |
+
# return tensors
|
| 544 |
+
input_ids = torch.tensor(input_ids, dtype=torch.long)
|
| 545 |
+
labels = torch.tensor([IGNORE_ID] * len(labels) if invalidate_label else labels, dtype=torch.long)
|
| 546 |
+
pixel_values = torch.cat(pixel_values, dim=0) if len(pixel_values) > 0 else None
|
| 547 |
+
|
| 548 |
+
if return_labels:
|
| 549 |
+
return prompt, input_ids, pixel_values, labels
|
| 550 |
+
else:
|
| 551 |
+
return prompt, input_ids, pixel_values
|
| 552 |
+
|
| 553 |
+
def save_pretrained(
|
| 554 |
+
self,
|
| 555 |
+
save_directory: Union[str, os.PathLike],
|
| 556 |
+
is_main_process: bool = True,
|
| 557 |
+
state_dict: Optional[dict] = None,
|
| 558 |
+
save_function: Callable = torch.save,
|
| 559 |
+
push_to_hub: bool = False,
|
| 560 |
+
max_shard_size: Union[int, str] = "5GB",
|
| 561 |
+
safe_serialization: bool = True,
|
| 562 |
+
variant: Optional[str] = None,
|
| 563 |
+
token: Optional[Union[str, bool]] = None,
|
| 564 |
+
save_peft_format: bool = True,
|
| 565 |
+
**kwargs
|
| 566 |
+
):
|
| 567 |
+
super().save_pretrained(save_directory,
|
| 568 |
+
is_main_process=is_main_process,
|
| 569 |
+
state_dict=state_dict,
|
| 570 |
+
save_function=save_function,
|
| 571 |
+
safe_serialization=safe_serialization)
|
| 572 |
+
self.get_text_tokenizer().save_pretrained(save_directory)
|
| 573 |
+
self.get_visual_tokenizer().get_image_processor().save_pretrained(save_directory)
|
| 574 |
+
|
| 575 |
+
def generate(
|
| 576 |
+
self,
|
| 577 |
+
inputs: Optional[torch.Tensor] = None,
|
| 578 |
+
**kwargs
|
| 579 |
+
) -> Union[GenerateOutput, torch.LongTensor]:
|
| 580 |
+
_, inputs_embeds, labels, attention_mask = self.merge_multimodal(
|
| 581 |
+
text_input_ids=inputs,
|
| 582 |
+
text_attention_masks=kwargs.pop('attention_mask'),
|
| 583 |
+
text_labels=None,
|
| 584 |
+
pixel_values=kwargs.pop('pixel_values'),
|
| 585 |
+
left_padding=True
|
| 586 |
+
)
|
| 587 |
+
inputs_embeds = inputs_embeds.detach()
|
| 588 |
+
torch.cuda.empty_cache()
|
| 589 |
+
|
| 590 |
+
return self.llm.generate(inputs=None, inputs_embeds=inputs_embeds, attention_mask=attention_mask, **kwargs)
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": {
|
| 3 |
+
"height": 448,
|
| 4 |
+
"width": 448
|
| 5 |
+
},
|
| 6 |
+
"do_center_crop": false,
|
| 7 |
+
"do_convert_rgb": true,
|
| 8 |
+
"do_normalize": true,
|
| 9 |
+
"do_rescale": true,
|
| 10 |
+
"do_resize": true,
|
| 11 |
+
"image_mean": [
|
| 12 |
+
0.48145466,
|
| 13 |
+
0.4578275,
|
| 14 |
+
0.40821073
|
| 15 |
+
],
|
| 16 |
+
"image_processor_type": "CLIPImageProcessor",
|
| 17 |
+
"image_std": [
|
| 18 |
+
0.26862954,
|
| 19 |
+
0.26130258,
|
| 20 |
+
0.27577711
|
| 21 |
+
],
|
| 22 |
+
"resample": 3,
|
| 23 |
+
"rescale_factor": 0.00392156862745098,
|
| 24 |
+
"size": {
|
| 25 |
+
"shortest_edge": 448
|
| 26 |
+
}
|
| 27 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>",
|
| 16 |
+
"<col>",
|
| 17 |
+
"<image>",
|
| 18 |
+
"<image_atom>",
|
| 19 |
+
"<image_pad>",
|
| 20 |
+
"<img>",
|
| 21 |
+
"<pre>",
|
| 22 |
+
"<row>",
|
| 23 |
+
"</img>"
|
| 24 |
+
],
|
| 25 |
+
"eos_token": {
|
| 26 |
+
"content": "<|im_end|>",
|
| 27 |
+
"lstrip": false,
|
| 28 |
+
"normalized": false,
|
| 29 |
+
"rstrip": false,
|
| 30 |
+
"single_word": false
|
| 31 |
+
},
|
| 32 |
+
"pad_token": {
|
| 33 |
+
"content": "<|endoftext|>",
|
| 34 |
+
"lstrip": false,
|
| 35 |
+
"normalized": false,
|
| 36 |
+
"rstrip": false,
|
| 37 |
+
"single_word": false
|
| 38 |
+
}
|
| 39 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c5ae00e602b8860cbd784ba82a8aa14e8feecec692e7076590d014d7b7fdafa
|
| 3 |
+
size 11421896
|