

Upload 6 files
Browse files- .gitattributes +2 -0
- README.md +55 -3
- colorization_modules.py +469 -0
- images/MODULES.png +0 -0
- images/empty +1 -0
- images/paper_images.jpg +3 -0
- images/paper_images.pdf +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/paper_images.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/paper_images.pdf filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,55 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Deep Colorization modules for Medical Image Analysis
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
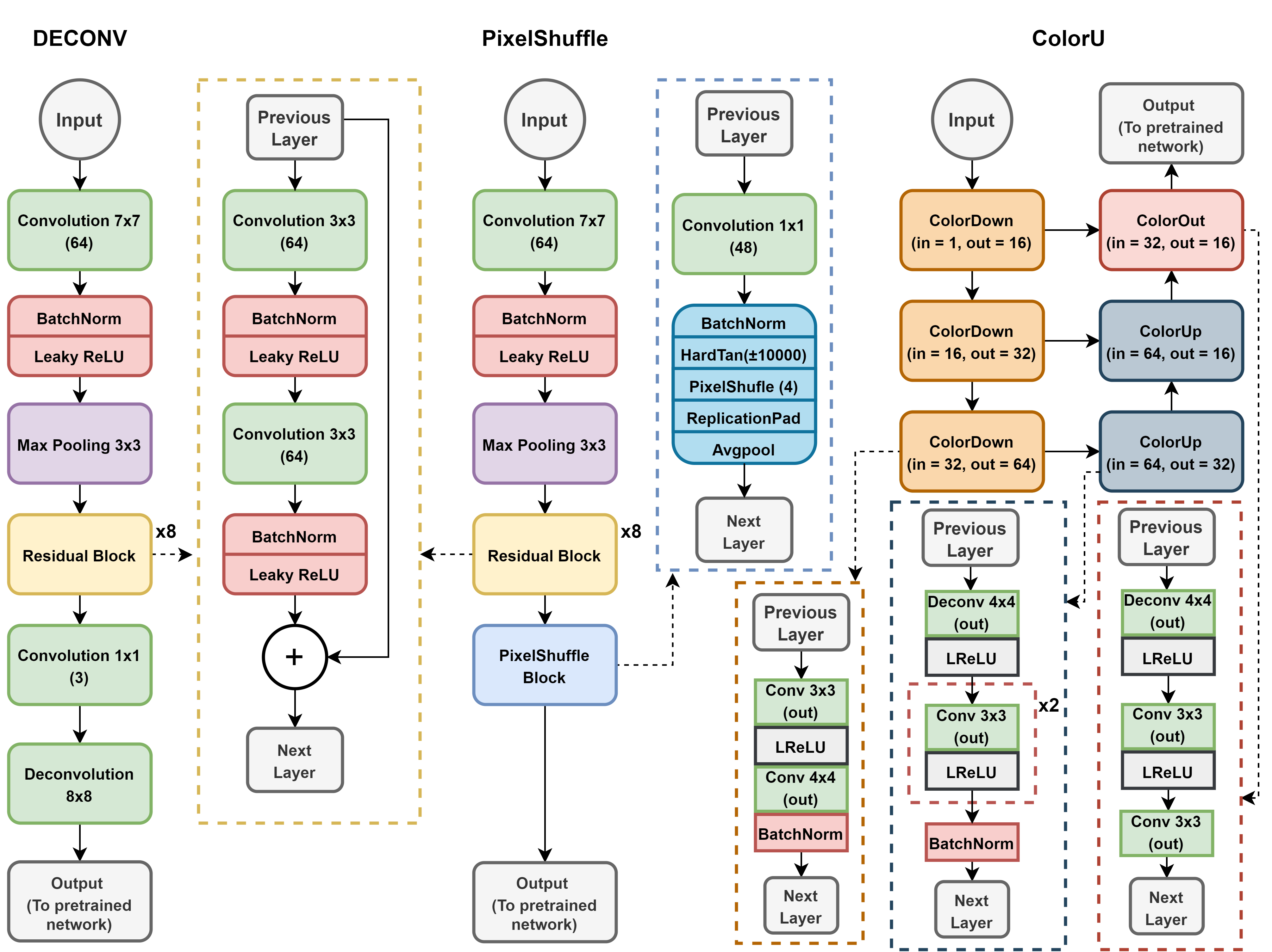
This project aims at bridging the gap between medical image analysis by introducing a light colorization module. Three different modules are proposed and implemented (DECONV, PixelShuffle and ColorU)
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+
|
| 9 |
+
The modules are trained jointly with a backbone pre-trained on ImageNet. A multi-stage transfer learning pipeline is summarized here.
|
| 10 |
+
First, the colorization module is trained from scratch together with the classifier, while the pre-trained CNN backbone is kept frozen, to learn the mapping which maximizes classification accuracy.
|
| 11 |
+
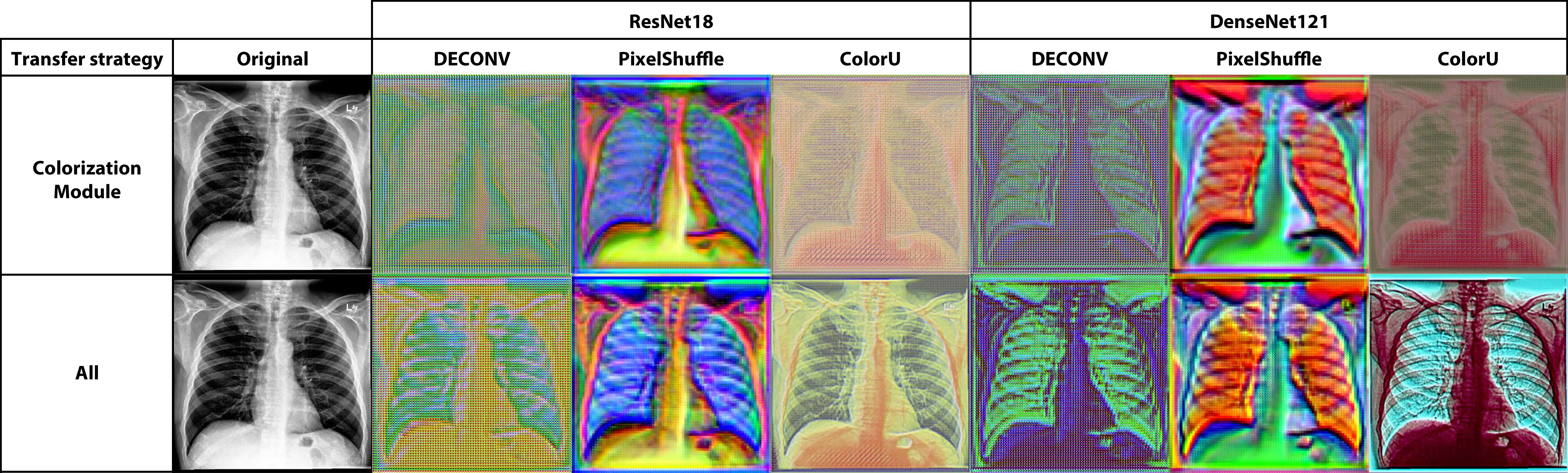
Then, the entire network is fine-tuned to learn useful features for the target task, while simultaneously adjusting the colorization mapping. The figure below shows the output of each colorization module when only the colorization module is trained, and after the entire network is fine-tuned.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+

|
| 15 |
+
|
| 16 |
+
## Dependencies
|
| 17 |
+
|
| 18 |
+
+ Linux
|
| 19 |
+
+ Python 3.7
|
| 20 |
+
+ PyTorch 1.4.0
|
| 21 |
+
|
| 22 |
+
## Download
|
| 23 |
+
|
| 24 |
+
Trained models with DenseNet121 and ResNet18 backbones are available [here](https://drive.google.com/drive/folders/1uwLd-rzkt7Fcph6RqR1Eq41aTh85XGb-?usp=sharing)
|
| 25 |
+
A detailed list of models is available [here](README_FILES.md)
|
| 26 |
+
|
| 27 |
+
All models were trained on [CheXpert](https://stanfordmlgroup.github.io/competitions/chexpert/) to predict the presence/absence of 5 labels:
|
| 28 |
+
+ Atelectasis
|
| 29 |
+
+ Cardiomegaly
|
| 30 |
+
+ Consolidation
|
| 31 |
+
+ Edema
|
| 32 |
+
+ Pleural Effusion
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
## Image normalization
|
| 36 |
+
If you wish to use the above models, please bear in mind that images were normalized with statistics calculated on the CheXPert dataset:
|
| 37 |
+
|
| 38 |
+
+ mean: [0.5028, 0.5028, 0.5028]
|
| 39 |
+
+ std: [0.2902, 0.2902, 0.2902]
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
# Citation
|
| 43 |
+
|
| 44 |
+
If you use the models in your research, please cite our paper:
|
| 45 |
+
|
| 46 |
+
```
|
| 47 |
+
@article{morra2020bridging,
|
| 48 |
+
title="Bridging the gap between Natural and Medical Images through Deep Colorization",
|
| 49 |
+
author="Morra, Lia and Piano, Luca and Lamberti, Fabrizio and Tommasi, Tatiana",
|
| 50 |
+
year="2020"
|
| 51 |
+
}
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
colorization_modules.py
ADDED
|
@@ -0,0 +1,469 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging as log
|
| 2 |
+
import os
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision.transforms as transforms
|
| 7 |
+
import torchvision.models as models
|
| 8 |
+
from torch import nn
|
| 9 |
+
from torch.nn import functional as F
|
| 10 |
+
|
| 11 |
+
from enum import Enum
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class AdvEnum(Enum):
|
| 15 |
+
@classmethod
|
| 16 |
+
def list(cls):
|
| 17 |
+
return list(map(lambda c: c.value, cls))
|
| 18 |
+
|
| 19 |
+
@classmethod
|
| 20 |
+
def list_name_value(cls):
|
| 21 |
+
return list(map(lambda c: (c.name, c.value), cls))
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class DecoNetMode(AdvEnum):
|
| 25 |
+
FREEZE_DECO = 0
|
| 26 |
+
FREEZE_PTMODEL = 1
|
| 27 |
+
FREEZE_PTMODEL_NO_FC = 2
|
| 28 |
+
UNFREEZE_ALL = 3
|
| 29 |
+
FREEZE_ALL = 4
|
| 30 |
+
FREEZE_ALL_NO_FC = 5
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class DecoType(AdvEnum):
|
| 34 |
+
NO = 0
|
| 35 |
+
DECONV = 1
|
| 36 |
+
RESIZE_CONV = 2
|
| 37 |
+
ColorUDECO = 16
|
| 38 |
+
PIXEL_SHUFFLE = 20
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_deco_model(use_deco, out_deco) -> nn.Module:
|
| 42 |
+
if use_deco in [DecoType.DECONV, DecoType.DECONV_NORM]:
|
| 43 |
+
return StandardDECO(out_deco, deconv=True)
|
| 44 |
+
elif use_deco in [DecoType.RESIZE_CONV]:
|
| 45 |
+
return StandardDECO(out_deco, deconv=False)
|
| 46 |
+
elif use_deco is DecoType.PIXEL_SHUFFLE:
|
| 47 |
+
return PixelShuffle(out_deco, lrelu=False)
|
| 48 |
+
elif use_deco is DecoType.ColorUDECO:
|
| 49 |
+
return ColorUDECO(out_deco)
|
| 50 |
+
else:
|
| 51 |
+
raise ValueError("Module not found")
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class PreTrainedModel(AdvEnum):
|
| 55 |
+
DENSENET_121 = 0
|
| 56 |
+
RESNET_18 = 1
|
| 57 |
+
RESNET_34 = 2
|
| 58 |
+
RESNET_50 = 3
|
| 59 |
+
VGG11 = 4
|
| 60 |
+
VGG11_BN = 5
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def get_pt_model(model, output, pretrained=True):
|
| 64 |
+
input = 224
|
| 65 |
+
if not isinstance(model, PreTrainedModel):
|
| 66 |
+
model = PreTrainedModel(model)
|
| 67 |
+
pt_model = None
|
| 68 |
+
if model == PreTrainedModel.DENSENET_121:
|
| 69 |
+
pt_model = models.densenet121(pretrained=pretrained)
|
| 70 |
+
num_ftrs = pt_model.classifier.in_features
|
| 71 |
+
pt_model.classifier = nn.Linear(num_ftrs, output)
|
| 72 |
+
pt_model.last_layer_name = "classifier"
|
| 73 |
+
elif model == PreTrainedModel.RESNET_18:
|
| 74 |
+
pt_model = models.resnet18(pretrained=pretrained)
|
| 75 |
+
num_ftrs = pt_model.fc.in_features
|
| 76 |
+
pt_model.fc = nn.Linear(num_ftrs, output)
|
| 77 |
+
pt_model.last_layer_name = "fc"
|
| 78 |
+
elif model == PreTrainedModel.RESNET_34:
|
| 79 |
+
pt_model = models.resnet34(pretrained=pretrained)
|
| 80 |
+
num_ftrs = pt_model.fc.in_features
|
| 81 |
+
pt_model.fc = nn.Linear(num_ftrs, output)
|
| 82 |
+
pt_model.last_layer_name = "fc"
|
| 83 |
+
elif model == PreTrainedModel.RESNET_50:
|
| 84 |
+
pt_model = models.resnet50(pretrained=pretrained)
|
| 85 |
+
num_ftrs = pt_model.fc.in_features
|
| 86 |
+
pt_model.fc = nn.Linear(num_ftrs, output)
|
| 87 |
+
pt_model.last_layer_name = "fc"
|
| 88 |
+
elif model == PreTrainedModel.VGG11:
|
| 89 |
+
pt_model = models.vgg11(pretrained=pretrained)
|
| 90 |
+
num_ftrs = pt_model.classifier[6].in_features
|
| 91 |
+
pt_model.classifier[6] = nn.Linear(num_ftrs, output)
|
| 92 |
+
pt_model.last_layer_name = "classifier.6"
|
| 93 |
+
elif model == PreTrainedModel.VGG11_BN:
|
| 94 |
+
pt_model = models.vgg11_bn(pretrained=pretrained)
|
| 95 |
+
num_ftrs = pt_model.classifier[6].in_features
|
| 96 |
+
pt_model.classifier[6] = nn.Linear(num_ftrs, output)
|
| 97 |
+
pt_model.last_layer_name = "classifier.6"
|
| 98 |
+
else:
|
| 99 |
+
raise ValueError("Model not found")
|
| 100 |
+
|
| 101 |
+
return pt_model, input
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class DecoNet(nn.Module):
|
| 105 |
+
"""
|
| 106 |
+
Colorization module(optional)+Model
|
| 107 |
+
"""
|
| 108 |
+
|
| 109 |
+
def __init__(self, output=14,
|
| 110 |
+
deco_type=DecoType.ColorUDECO,
|
| 111 |
+
pt_model=PreTrainedModel.RESNET_18,
|
| 112 |
+
pre_trained=True,
|
| 113 |
+
training_mode=DecoNetMode.FREEZE_PTMODEL_NO_FC,
|
| 114 |
+
use_aap=False):
|
| 115 |
+
super().__init__()
|
| 116 |
+
# Pre-trained Model
|
| 117 |
+
self.deco_type = deco_type
|
| 118 |
+
self.training_mode = training_mode
|
| 119 |
+
self.use_aap = use_aap
|
| 120 |
+
pt_model, self.out_deco = get_pt_model(pt_model, output, pre_trained)
|
| 121 |
+
self.last_layer_name = pt_model.last_layer_name
|
| 122 |
+
# DECO if needed
|
| 123 |
+
if self.deco_type is not DecoType.NO:
|
| 124 |
+
self.deco = get_deco_model(self.deco_type, self.out_deco)
|
| 125 |
+
else:
|
| 126 |
+
self.deco = None
|
| 127 |
+
self.pt_model = pt_model
|
| 128 |
+
self.set_mode(training_mode)
|
| 129 |
+
|
| 130 |
+
def set_mode(self, mode, print=True):
|
| 131 |
+
if not isinstance(mode, DecoNetMode):
|
| 132 |
+
mode = DecoNetMode(mode)
|
| 133 |
+
if mode == DecoNetMode.UNFREEZE_ALL:
|
| 134 |
+
for param in self.parameters():
|
| 135 |
+
param.requires_grad = True
|
| 136 |
+
elif mode == DecoNetMode.FREEZE_DECO:
|
| 137 |
+
self.set_mode(DecoNetMode.UNFREEZE_ALL, False)
|
| 138 |
+
for param in self.deco.parameters():
|
| 139 |
+
param.requires_grad = False
|
| 140 |
+
elif mode == DecoNetMode.FREEZE_PTMODEL:
|
| 141 |
+
self.set_mode(DecoNetMode.UNFREEZE_ALL, False)
|
| 142 |
+
for param in self.pt_model.parameters():
|
| 143 |
+
param.requires_grad = False
|
| 144 |
+
elif mode == DecoNetMode.FREEZE_PTMODEL_NO_FC:
|
| 145 |
+
self.set_mode(DecoNetMode.UNFREEZE_ALL, False)
|
| 146 |
+
for name, param in self.pt_model.named_parameters():
|
| 147 |
+
if self.last_layer_name not in name:
|
| 148 |
+
param.requires_grad = False
|
| 149 |
+
elif mode == DecoNetMode.FREEZE_ALL:
|
| 150 |
+
for param in self.parameters():
|
| 151 |
+
param.requires_grad = False
|
| 152 |
+
elif mode == DecoNetMode.FREEZE_ALL_NO_FC:
|
| 153 |
+
self.set_mode(DecoNetMode.FREEZE_ALL, False)
|
| 154 |
+
# Unfreeze last layer
|
| 155 |
+
for name, param in self.pt_model.named_parameters():
|
| 156 |
+
if self.last_layer_name in name:
|
| 157 |
+
param.requires_grad = True
|
| 158 |
+
|
| 159 |
+
if print:
|
| 160 |
+
log.info("#############################################")
|
| 161 |
+
log.info("PARAMETERS STATUS:")
|
| 162 |
+
for name, param in self.named_parameters():
|
| 163 |
+
log.info("{} : {}".format(name, param.requires_grad))
|
| 164 |
+
log.info("#############################################")
|
| 165 |
+
|
| 166 |
+
def get_layer_weight(self, sel_name: str = ""):
|
| 167 |
+
if sel_name == "":
|
| 168 |
+
sel_name = self.last_layer_name
|
| 169 |
+
res = []
|
| 170 |
+
for name, param in self.pt_model.named_parameters():
|
| 171 |
+
if sel_name in name:
|
| 172 |
+
res.append(param)
|
| 173 |
+
|
| 174 |
+
return res
|
| 175 |
+
|
| 176 |
+
def forward(self, xb):
|
| 177 |
+
"""
|
| 178 |
+
@:param xb : tensor
|
| 179 |
+
Batch of input images
|
| 180 |
+
|
| 181 |
+
@:return tensor
|
| 182 |
+
A batch of output images
|
| 183 |
+
"""
|
| 184 |
+
if self.deco is not None:
|
| 185 |
+
xb = self.deco(xb)
|
| 186 |
+
if self.use_aap:
|
| 187 |
+
xb = F.adaptive_avg_pool2d(xb, (self.out_deco, self.out_deco))
|
| 188 |
+
return self.pt_model(xb)
|
| 189 |
+
|
| 190 |
+
def clean_last_layer(self):
|
| 191 |
+
pt_model_type = self.pt_model
|
| 192 |
+
|
| 193 |
+
if pt_model_type == PreTrainedModel.VGG11_BN or pt_model_type == PreTrainedModel.VGG11:
|
| 194 |
+
self.pt_model.classifier[6].reset_parameters()
|
| 195 |
+
else:
|
| 196 |
+
last_layer_name = list(self.pt_model._modules)[-1]
|
| 197 |
+
self.pt_model._modules[last_layer_name].reset_parameters()
|
| 198 |
+
|
| 199 |
+
log.info("Last layer cleaned!")
|
| 200 |
+
|
| 201 |
+
def last_layer_size(self):
|
| 202 |
+
pt_model_type = self.pt_model
|
| 203 |
+
if pt_model_type == PreTrainedModel.VGG11_BN or pt_model_type == PreTrainedModel.VGG11:
|
| 204 |
+
return self.pt_model.classifier[6].weight.shape[-1]
|
| 205 |
+
else:
|
| 206 |
+
last_layer_name = list(self.pt_model._modules)[-1]
|
| 207 |
+
return self.pt_model._modules[last_layer_name].shape[-1]
|
| 208 |
+
|
| 209 |
+
def load_deco_state_dict(self, state_dict):
|
| 210 |
+
if self.deco is None:
|
| 211 |
+
self.deco = get_deco_model(self.deco_type, self.out_deco)
|
| 212 |
+
if hasattr(self.deco, "load_state_dict"):
|
| 213 |
+
self.deco.load_state_dict(state_dict)
|
| 214 |
+
else:
|
| 215 |
+
return False
|
| 216 |
+
self.set_mode(self.training_mode)
|
| 217 |
+
return True
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def default_deco__weight_init(m):
|
| 221 |
+
if isinstance(m, nn.Conv2d):
|
| 222 |
+
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 223 |
+
# m.weight.data.normal_(0, math.sqrt(2. / n))
|
| 224 |
+
torch.nn.init.xavier_uniform_(m.weight)
|
| 225 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 226 |
+
m.weight.data.fill_(1)
|
| 227 |
+
m.bias.data.zero_()
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
def bn_weight_init(m):
|
| 231 |
+
if isinstance(m, nn.BatchNorm2d):
|
| 232 |
+
m.weight.data.fill_(1)
|
| 233 |
+
m.bias.data.zero_()
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
class BaseDECO(nn.Module):
|
| 237 |
+
def __init__(self, out=224, init=None):
|
| 238 |
+
super().__init__()
|
| 239 |
+
self.out_s = out
|
| 240 |
+
self.init = init
|
| 241 |
+
|
| 242 |
+
def set_output_size(self, out_s):
|
| 243 |
+
self.out_s = out_s
|
| 244 |
+
|
| 245 |
+
def init_weights(self):
|
| 246 |
+
if self.init is None:
|
| 247 |
+
pass
|
| 248 |
+
elif self.init == 0:
|
| 249 |
+
self.apply(default_deco__weight_init)
|
| 250 |
+
elif self.init == 1:
|
| 251 |
+
self.apply(bn_weight_init)
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
class ResBlock(nn.Module):
|
| 255 |
+
def __init__(self, ni, nf=None, kernel=3, stride=1, padding=1):
|
| 256 |
+
super().__init__()
|
| 257 |
+
if nf is None:
|
| 258 |
+
nf = ni
|
| 259 |
+
self.conv1 = conv_layer(ni, nf, kernel=kernel, stride=stride, padding=padding)
|
| 260 |
+
self.conv2 = conv_layer(nf, nf, kernel=kernel, stride=stride, padding=padding)
|
| 261 |
+
|
| 262 |
+
def forward(self, x):
|
| 263 |
+
return x + self.conv2(self.conv1(x))
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def conv_layer(in_layer, out_layer, kernel=3, stride=1, padding=1, instanceNorm=False):
|
| 267 |
+
return nn.Sequential(
|
| 268 |
+
nn.Conv2d(in_layer, out_layer, kernel_size=kernel, stride=stride, padding=padding),
|
| 269 |
+
nn.BatchNorm2d(out_layer) if not instanceNorm else nn.InstanceNorm2d(out_layer),
|
| 270 |
+
nn.LeakyReLU(inplace=True)
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
def _make_res_layers(nl, ni, kernel=3, stride=1, padding=1):
|
| 275 |
+
layers = []
|
| 276 |
+
for i in range(nl):
|
| 277 |
+
layers.append(ResBlock(ni, kernel=kernel, stride=stride, padding=padding))
|
| 278 |
+
|
| 279 |
+
return nn.Sequential(*layers)
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
class StandardDECO(BaseDECO):
|
| 283 |
+
"""
|
| 284 |
+
Standard DECO Module
|
| 285 |
+
"""
|
| 286 |
+
|
| 287 |
+
def __init__(self, out=224, init=0, deconv=False):
|
| 288 |
+
super().__init__(out, init)
|
| 289 |
+
self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=2)
|
| 290 |
+
self.bn1 = nn.BatchNorm2d(64)
|
| 291 |
+
# ReLU
|
| 292 |
+
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 293 |
+
self.resblocks = _make_res_layers(8, 64)
|
| 294 |
+
self.conv_last = nn.Conv2d(64, 3, kernel_size=1)
|
| 295 |
+
self.deconv = deconv
|
| 296 |
+
if deconv:
|
| 297 |
+
# TODO: Check if use "groups = 1"
|
| 298 |
+
self.deconv = nn.ConvTranspose2d(in_channels=3, out_channels=3, kernel_size=8, padding=2, stride=4,
|
| 299 |
+
groups=3, bias=False)
|
| 300 |
+
else:
|
| 301 |
+
self.pad = nn.ReflectionPad2d(1)
|
| 302 |
+
self.conv_up = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, padding=0, stride=1)
|
| 303 |
+
|
| 304 |
+
self.init_weights()
|
| 305 |
+
|
| 306 |
+
def forward(self, xb):
|
| 307 |
+
"""
|
| 308 |
+
@:param xb : Tensor
|
| 309 |
+
Batch of input images
|
| 310 |
+
|
| 311 |
+
@:return tensor
|
| 312 |
+
A batch of output images
|
| 313 |
+
"""
|
| 314 |
+
_xb = self.maxpool(F.leaky_relu(self.bn1(self.conv1(xb))))
|
| 315 |
+
_xb = self.resblocks(_xb)
|
| 316 |
+
_xb = self.conv_last(_xb)
|
| 317 |
+
if self.deconv:
|
| 318 |
+
_xb = self.deconv(_xb, output_size=xb.shape)
|
| 319 |
+
else:
|
| 320 |
+
_xb = self.conv_up(self.pad(F.interpolate(_xb, scale_factor=4, mode='nearest')))
|
| 321 |
+
return _xb
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
def icnr(x, scale=4, init=nn.init.kaiming_normal_):
|
| 325 |
+
""" ICNR init of `x`, with `scale` and `init` function.
|
| 326 |
+
|
| 327 |
+
Checkerboard artifact free sub-pixel convolution: https://arxiv.org/ftp/arxiv/papers/1707/1707.02937.pdf
|
| 328 |
+
"""
|
| 329 |
+
ni, nf, h, w = x.shape
|
| 330 |
+
ni2 = int(ni / (scale ** 2))
|
| 331 |
+
k = init(torch.zeros([ni2, nf, h, w])).transpose(0, 1)
|
| 332 |
+
k = k.contiguous().view(ni2, nf, -1)
|
| 333 |
+
k = k.repeat(1, 1, scale ** 2)
|
| 334 |
+
k = k.contiguous().view([nf, ni, h, w]).transpose(0, 1)
|
| 335 |
+
x.data.copy_(k)
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
class PixelShuffle_ICNR(nn.Module):
|
| 339 |
+
""" Upsample by `scale` from `ni` filters to `nf` (default `ni`), using `nn.PixelShuffle`, `icnr` init,
|
| 340 |
+
and `weight_norm`.
|
| 341 |
+
|
| 342 |
+
"Super-Resolution using Convolutional Neural Networks without Any Checkerboard Artifacts":
|
| 343 |
+
https://arxiv.org/abs/1806.02658
|
| 344 |
+
"""
|
| 345 |
+
|
| 346 |
+
def __init__(self, ni: int, nf: int = None, scale: int = 4, icnr_init=True, blur_k=2, blur_s=1,
|
| 347 |
+
blur_pad=(1, 0, 1, 0), lrelu=True):
|
| 348 |
+
super().__init__()
|
| 349 |
+
nf = ni if nf is None else nf
|
| 350 |
+
self.conv = conv_layer(ni, nf * (scale ** 2), kernel=1, padding=0, stride=1) if lrelu else nn.Sequential(
|
| 351 |
+
nn.Conv2d(64, 3 * (scale ** 2), 1, 1, 0), nn.BatchNorm2d(3 * (scale ** 2)))
|
| 352 |
+
if icnr_init:
|
| 353 |
+
icnr(self.conv[0].weight, scale=scale)
|
| 354 |
+
self.act = nn.LeakyReLU(inplace=False) if lrelu else nn.Hardtanh(-10000, 10000)
|
| 355 |
+
self.shuf = nn.PixelShuffle(scale)
|
| 356 |
+
# Blurring over (h*w) kernel
|
| 357 |
+
self.pad = nn.ReplicationPad2d(blur_pad)
|
| 358 |
+
self.blur = nn.AvgPool2d(blur_k, stride=blur_s)
|
| 359 |
+
|
| 360 |
+
def forward(self, x):
|
| 361 |
+
x = self.shuf(self.act(self.conv(x)))
|
| 362 |
+
return self.blur(self.pad(x))
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
class PixelShuffle(BaseDECO):
|
| 366 |
+
"""
|
| 367 |
+
PixelShuffle Module
|
| 368 |
+
"""
|
| 369 |
+
|
| 370 |
+
def __init__(self, out=224, init=1, scale=4, lrelu=False):
|
| 371 |
+
super().__init__(out, init)
|
| 372 |
+
# Which value should I use for stride and padding?
|
| 373 |
+
self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=2)
|
| 374 |
+
self.bn1 = nn.BatchNorm2d(64)
|
| 375 |
+
self.act1 = nn.LeakyReLU()
|
| 376 |
+
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 377 |
+
self.resblocks = _make_res_layers(8, 64)
|
| 378 |
+
self.pixel_shuffle = PixelShuffle_ICNR(ni=64, nf=3, scale=scale, lrelu=lrelu)
|
| 379 |
+
self.init_weights()
|
| 380 |
+
|
| 381 |
+
def forward(self, xb):
|
| 382 |
+
"""
|
| 383 |
+
@:param xb : Tensor
|
| 384 |
+
Batch of input images
|
| 385 |
+
|
| 386 |
+
@:return tensor
|
| 387 |
+
A batch of output images
|
| 388 |
+
"""
|
| 389 |
+
_xb = self.maxpool(self.act1(self.bn1(self.conv1(xb))))
|
| 390 |
+
_xb = self.resblocks(_xb)
|
| 391 |
+
|
| 392 |
+
return self.pixel_shuffle(_xb)
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
class ColorUDECO(BaseDECO):
|
| 396 |
+
"""
|
| 397 |
+
ColorUDECO Module
|
| 398 |
+
"""
|
| 399 |
+
|
| 400 |
+
def __init__(self, out=224, init=0, in_ch=1, out_ch=3):
|
| 401 |
+
super().__init__(out, init)
|
| 402 |
+
self.dw1 = ColorDown(in_ch, 16)
|
| 403 |
+
self.dw2 = ColorDown(16, 32)
|
| 404 |
+
self.dw3 = ColorDown(32, 64)
|
| 405 |
+
self.up1 = ColorUp(64, 32)
|
| 406 |
+
self.up2 = ColorUp(64, 16)
|
| 407 |
+
self.out = ColorOut(32, 16, out_ch)
|
| 408 |
+
|
| 409 |
+
def forward(self, x1):
|
| 410 |
+
"""
|
| 411 |
+
@:param x1 : Tensor
|
| 412 |
+
Batch of input images
|
| 413 |
+
|
| 414 |
+
@:return tensor
|
| 415 |
+
A batch of output images
|
| 416 |
+
"""
|
| 417 |
+
x1 = self.dw1(x1)
|
| 418 |
+
x2 = self.dw2(x1)
|
| 419 |
+
x3 = self.dw3(x2)
|
| 420 |
+
x3 = self.up1(x3)
|
| 421 |
+
x2 = self.up2(torch.cat([x2, x3], dim=1))
|
| 422 |
+
return self.out(torch.cat([x1, x2], dim=1))
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
class ColorDown(nn.Module):
|
| 426 |
+
def __init__(self, in_ch, out_ch, htan=False):
|
| 427 |
+
super(ColorDown, self).__init__()
|
| 428 |
+
self.d = nn.Sequential(
|
| 429 |
+
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1),
|
| 430 |
+
nn.LeakyReLU() if not htan else nn.Hardtanh(),
|
| 431 |
+
nn.Conv2d(out_ch, out_ch, kernel_size=4, stride=2, padding=1),
|
| 432 |
+
nn.LeakyReLU() if not htan else nn.Hardtanh(),
|
| 433 |
+
nn.BatchNorm2d(out_ch)
|
| 434 |
+
)
|
| 435 |
+
|
| 436 |
+
def forward(self, x):
|
| 437 |
+
return self.d(x)
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
class ColorUp(nn.Module):
|
| 441 |
+
def __init__(self, in_ch, out_ch, htan=False):
|
| 442 |
+
super(ColorUp, self).__init__()
|
| 443 |
+
self.u = nn.Sequential(
|
| 444 |
+
nn.ConvTranspose2d(in_ch, out_ch, 4, 2, 1),
|
| 445 |
+
nn.LeakyReLU() if not htan else nn.Hardtanh(),
|
| 446 |
+
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1),
|
| 447 |
+
nn.LeakyReLU() if not htan else nn.Hardtanh(),
|
| 448 |
+
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1),
|
| 449 |
+
nn.LeakyReLU() if not htan else nn.Hardtanh(),
|
| 450 |
+
nn.BatchNorm2d(out_ch)
|
| 451 |
+
)
|
| 452 |
+
|
| 453 |
+
def forward(self, x):
|
| 454 |
+
return self.u(x)
|
| 455 |
+
|
| 456 |
+
|
| 457 |
+
class ColorOut(nn.Module):
|
| 458 |
+
def __init__(self, in_ch, out_ch, out_last, htan=False):
|
| 459 |
+
super(ColorOut, self).__init__()
|
| 460 |
+
self.u = nn.Sequential(
|
| 461 |
+
nn.ConvTranspose2d(in_ch, out_ch, 4, 2, 1),
|
| 462 |
+
nn.LeakyReLU() if not htan else nn.Hardtanh(),
|
| 463 |
+
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1),
|
| 464 |
+
nn.LeakyReLU() if not htan else nn.Hardtanh(),
|
| 465 |
+
nn.Conv2d(out_ch, out_last, kernel_size=1, stride=1, padding=0),
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
def forward(self, x):
|
| 469 |
+
return self.u(x)
|
images/MODULES.png
ADDED
|
images/empty
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
images/paper_images.jpg
ADDED
|
Git LFS Details
|
images/paper_images.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4d46d8be627e5d96c592be306e9c74b91a2412cbbc05bead81e3a12082915b89
|
| 3 |
+
size 1271680
|