
File size: 1,515 Bytes
3fd0224 d578be4 3fd0224 32d703a 7bde159 32d703a 08c544d e086b09 d4b0dfe fc46d14 a465cbf fc46d14 70a5722 fc46d14 0d92d86 1274c18 cc01c1e 0d92d86 32d703a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
---
license: cc-by-nc-4.0
inference: false
pipeline_tag: text-generation
tags:
- gguf
- quantized
- text-generation-inference
---
**GGUF-IQ-Imatrix-Quantization-Script:**
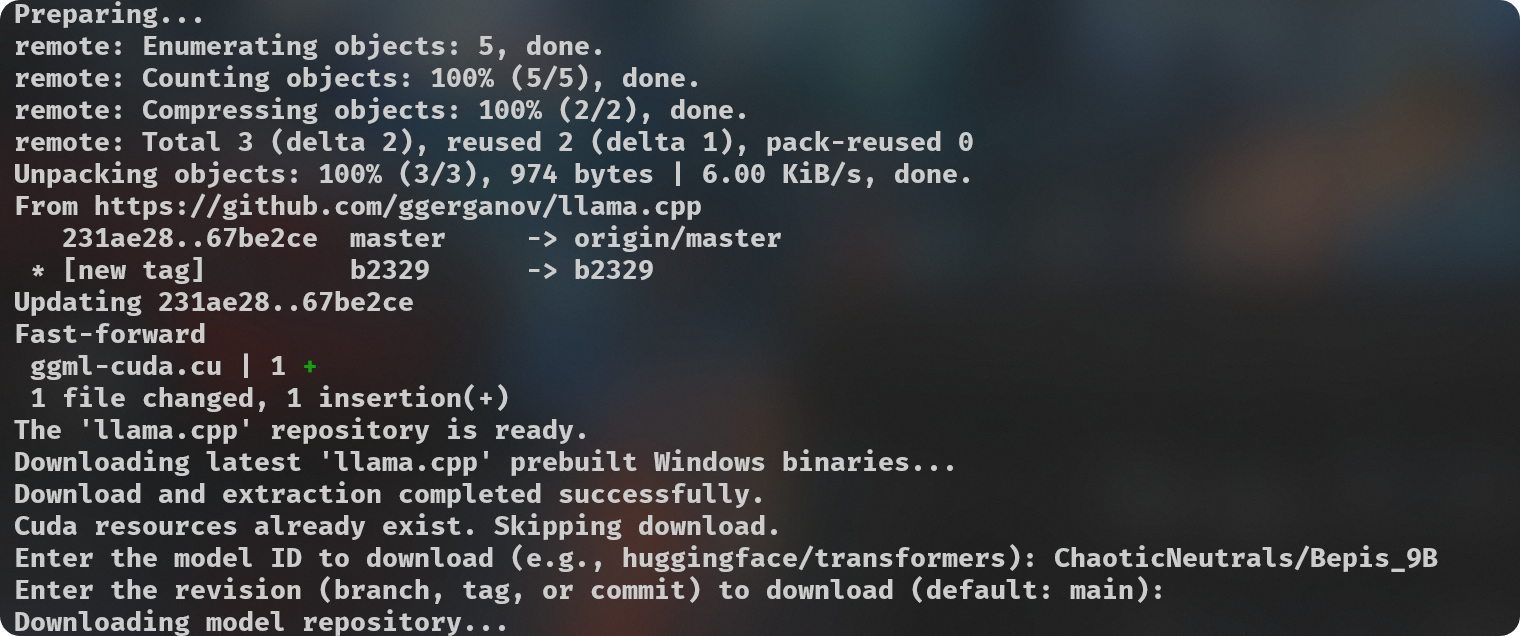
Simple python script (`gguf-imat.py`) to generate various GGUF-IQ-Imatrix quantizations from a Hugging Face `author/model` input, for Windows and NVIDIA hardware.
This is setup for a Windows machine with 8GB of VRAM, assuming use with an NVIDIA GPU. If you want to change the the `-ngl` (number of GPU layers) amount, you can do so at **line 120**. This is only relevant during the `--imatrix` data generation. If you don't have enough VRAM you can decrease the `-ngl` amount or set it to 0 to only use your System RAM instead for all layers.
Your `imatrix.txt` is expected to be located inside the `imatrix` folder. Included file is considered a good option, [this discussion](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384) is where it came from.
Adjust `quantization_options` in **line 133**.
**Requirements:**
- Git
- Python 3.11
- `pip install huggingface_hub`
**Usage:**
```
python .\gguf-imat.py
```
Quantizations will be output into the created `models\{model-name}-GGUF` folder.
<br><br>
### **Credits:**
**If this proves useful for you, feel free to credit and share the repository.**
**Made in conjunction with [@Lewdiculous](https://huggingface.co/Lewdiculous).** |