
Commit
·
8a72672
1
Parent(s):
9aef615
Upload 8 files
Browse files- config.json +37 -0
- history.csv +16 -0
- output.png +0 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +7 -0
- tokenizer_config.json +19 -0
- training_args.bin +3 -0
- vocab.txt +0 -0
config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "cl-tohoku/bert-base-japanese-whole-word-masking",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_dropout_prob": 0.1,
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"id2label": {
|
| 12 |
+
"0": "positive",
|
| 13 |
+
"1": "neutral",
|
| 14 |
+
"2": "negative"
|
| 15 |
+
},
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"intermediate_size": 3072,
|
| 18 |
+
"label2id": {
|
| 19 |
+
"negative": 2,
|
| 20 |
+
"neutral": 1,
|
| 21 |
+
"positive": 0
|
| 22 |
+
},
|
| 23 |
+
"layer_norm_eps": 1e-12,
|
| 24 |
+
"max_position_embeddings": 512,
|
| 25 |
+
"model_type": "bert",
|
| 26 |
+
"num_attention_heads": 12,
|
| 27 |
+
"num_hidden_layers": 12,
|
| 28 |
+
"pad_token_id": 0,
|
| 29 |
+
"position_embedding_type": "absolute",
|
| 30 |
+
"problem_type": "single_label_classification",
|
| 31 |
+
"tokenizer_class": "BertJapaneseTokenizer",
|
| 32 |
+
"torch_dtype": "float32",
|
| 33 |
+
"transformers_version": "4.33.2",
|
| 34 |
+
"type_vocab_size": 2,
|
| 35 |
+
"use_cache": true,
|
| 36 |
+
"vocab_size": 32000
|
| 37 |
+
}
|
history.csv
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
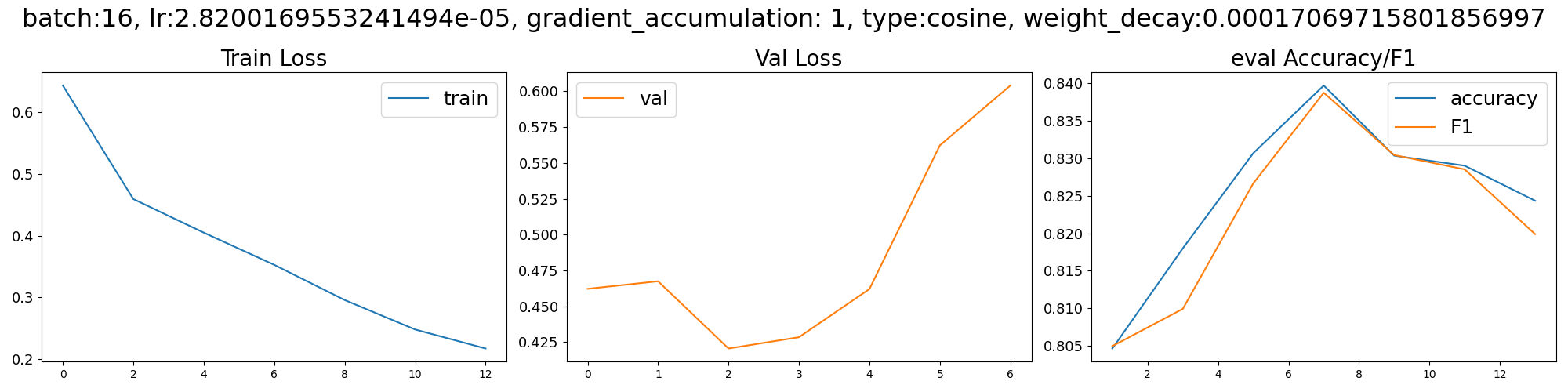
,loss,learning_rate,epoch,step,eval_loss,eval_accuracy,eval_f1,eval_runtime,eval_samples_per_second,eval_steps_per_second,train_runtime,train_samples_per_second,train_steps_per_second,total_flos,train_loss
|
| 2 |
+
0,0.6437,2.8185129462813098e-06,1.0,7500,,,,,,,,,,,
|
| 3 |
+
1,,,1.0,7500,0.4621545076370239,0.8046666666666666,0.8049857966154991,4.091,733.314,45.954,,,,,
|
| 4 |
+
2,0.4596,5.6377778970840395e-06,2.0,15000,,,,,,,,,,,
|
| 5 |
+
3,,,2.0,15000,0.46744176745414734,0.818,0.8099413139021953,4.096,732.417,45.898,,,,,
|
| 6 |
+
4,0.4051,8.456666845626058e-06,3.0,22500,,,,,,,,,,,
|
| 7 |
+
5,,,3.0,22500,0.4205056428909302,0.8306666666666667,0.8266481080596656,4.0971,732.222,45.886,,,,,
|
| 8 |
+
6,0.3529,1.127593179642879e-05,4.0,30000,,,,,,,,,,,
|
| 9 |
+
7,,,4.0,30000,0.42838728427886963,0.8396666666666667,0.8387062437364164,4.0957,732.479,45.902,,,,,
|
| 10 |
+
8,0.2958,1.40944447427101e-05,5.0,37500,,,,,,,,,,,
|
| 11 |
+
9,,,5.0,37500,0.4620000720024109,0.8303333333333334,0.8304119496302145,4.0916,733.209,45.948,,,,,
|
| 12 |
+
10,0.248,1.691370969351283e-05,6.0,45000,,,,,,,,,,,
|
| 13 |
+
11,,,6.0,45000,0.5622704029083252,0.829,0.8285084230864971,4.0992,731.853,45.863,,,,,
|
| 14 |
+
12,0.2172,1.9732598642054846e-05,7.0,52500,,,,,,,,,,,
|
| 15 |
+
13,,,7.0,52500,0.6040271520614624,0.8243333333333334,0.8198857071905551,4.0953,732.547,45.906,,,,,
|
| 16 |
+
14,,,7.0,52500,,,,,,,4427.9199,2710.076,169.38,8.609884212966826e+16,0.3746183896019345
|
output.png
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d73c306825e8efdd493c34a2be25e47e0f03388b82ea0785cdceb6a9c8c97bd
|
| 3 |
+
size 442545135
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"clean_up_tokenization_spaces": true,
|
| 3 |
+
"cls_token": "[CLS]",
|
| 4 |
+
"do_lower_case": false,
|
| 5 |
+
"do_subword_tokenize": true,
|
| 6 |
+
"do_word_tokenize": true,
|
| 7 |
+
"jumanpp_kwargs": null,
|
| 8 |
+
"mask_token": "[MASK]",
|
| 9 |
+
"mecab_kwargs": null,
|
| 10 |
+
"model_max_length": 512,
|
| 11 |
+
"never_split": null,
|
| 12 |
+
"pad_token": "[PAD]",
|
| 13 |
+
"sep_token": "[SEP]",
|
| 14 |
+
"subword_tokenizer_type": "wordpiece",
|
| 15 |
+
"sudachi_kwargs": null,
|
| 16 |
+
"tokenizer_class": "BertJapaneseTokenizer",
|
| 17 |
+
"unk_token": "[UNK]",
|
| 18 |
+
"word_tokenizer_type": "mecab"
|
| 19 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:08018957f1ceccd358a7f444c54bcd5302c35cffa6c52ecb4bd8c9e7c67d065f
|
| 3 |
+
size 4079
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|