
Commit
·
8cc39f8
1
Parent(s):
8e5f811
Upload 8 files
Browse files- config.json +37 -0
- history.csv +16 -0
- output.png +0 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +7 -0
- tokenizer_config.json +19 -0
- training_args.bin +3 -0
- vocab.txt +0 -0
config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "cl-tohoku/bert-base-japanese-whole-word-masking",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"classifier_dropout": null,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_dropout_prob": 0.1,
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"id2label": {
|
| 12 |
+
"0": "positive",
|
| 13 |
+
"1": "neutral",
|
| 14 |
+
"2": "negative"
|
| 15 |
+
},
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"intermediate_size": 3072,
|
| 18 |
+
"label2id": {
|
| 19 |
+
"negative": 2,
|
| 20 |
+
"neutral": 1,
|
| 21 |
+
"positive": 0
|
| 22 |
+
},
|
| 23 |
+
"layer_norm_eps": 1e-12,
|
| 24 |
+
"max_position_embeddings": 512,
|
| 25 |
+
"model_type": "bert",
|
| 26 |
+
"num_attention_heads": 12,
|
| 27 |
+
"num_hidden_layers": 12,
|
| 28 |
+
"pad_token_id": 0,
|
| 29 |
+
"position_embedding_type": "absolute",
|
| 30 |
+
"problem_type": "single_label_classification",
|
| 31 |
+
"tokenizer_class": "BertJapaneseTokenizer",
|
| 32 |
+
"torch_dtype": "float32",
|
| 33 |
+
"transformers_version": "4.33.2",
|
| 34 |
+
"type_vocab_size": 2,
|
| 35 |
+
"use_cache": true,
|
| 36 |
+
"vocab_size": 32000
|
| 37 |
+
}
|
history.csv
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
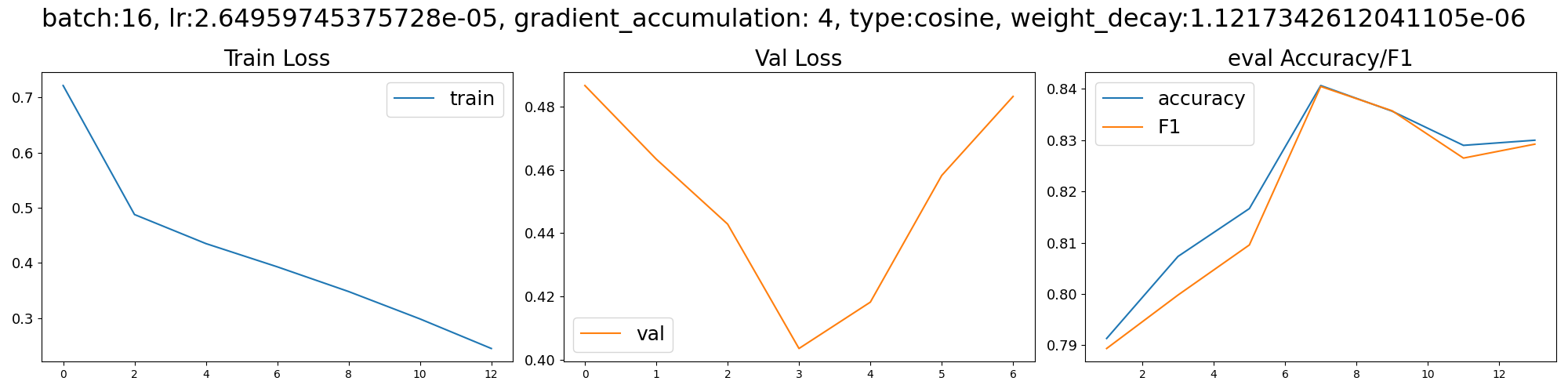
,loss,learning_rate,epoch,step,eval_loss,eval_accuracy,eval_f1,eval_runtime,eval_samples_per_second,eval_steps_per_second,train_runtime,train_samples_per_second,train_steps_per_second,total_flos,train_loss
|
| 2 |
+
0,0.7214,2.6481843351152765e-06,1.0,1875,,,,,,,,,,,
|
| 3 |
+
1,,,1.0,1875,0.486614465713501,0.7913333333333333,0.7893769545943459,4.0919,733.153,45.944,,,,,
|
| 4 |
+
2,0.4877,5.296368670230553e-06,2.0,3750,,,,,,,,,,,
|
| 5 |
+
3,,,2.0,3750,0.4633776843547821,0.8073333333333333,0.799803348055785,4.0931,732.948,45.931,,,,,
|
| 6 |
+
4,0.4351,7.945966123987833e-06,3.0,5625,,,,,,,,,,,
|
| 7 |
+
5,,,3.0,5625,0.44285982847213745,0.8166666666666667,0.8095748253721257,4.1043,730.946,45.806,,,,,
|
| 8 |
+
6,0.393,1.0594150459103109e-05,4.0,7500,,,,,,,,,,,
|
| 9 |
+
7,,,4.0,7500,0.40357911586761475,0.8406666666666667,0.8404833951539175,4.0943,732.728,45.918,,,,,
|
| 10 |
+
8,0.3482,1.3243747912860389e-05,5.0,9375,,,,,,,,,,,
|
| 11 |
+
9,,,5.0,9375,0.4182170331478119,0.8356666666666667,0.8357453865927326,4.0925,733.053,45.938,,,,,
|
| 12 |
+
10,0.2986,1.5890519129333662e-05,6.0,11250,,,,,,,,,,,
|
| 13 |
+
11,,,6.0,11250,0.4582119286060333,0.829,0.8265142641408832,4.0926,733.022,45.936,,,,,
|
| 14 |
+
12,0.245,1.853870346444894e-05,7.0,13125,,,,,,,,,,,
|
| 15 |
+
13,,,7.0,13125,0.4831666350364685,0.83,0.8292331918796845,4.0936,732.859,45.926,,,,,
|
| 16 |
+
14,,,7.0,13125,,,,,,,3769.8628,3183.14,49.737,8.609884212966826e+16,0.4184326125372024
|
output.png
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f536b1dbc0ea6a3ed65ab13e43d7ebd73ec26534ca76e836dca75e43af0567c
|
| 3 |
+
size 442545135
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"clean_up_tokenization_spaces": true,
|
| 3 |
+
"cls_token": "[CLS]",
|
| 4 |
+
"do_lower_case": false,
|
| 5 |
+
"do_subword_tokenize": true,
|
| 6 |
+
"do_word_tokenize": true,
|
| 7 |
+
"jumanpp_kwargs": null,
|
| 8 |
+
"mask_token": "[MASK]",
|
| 9 |
+
"mecab_kwargs": null,
|
| 10 |
+
"model_max_length": 512,
|
| 11 |
+
"never_split": null,
|
| 12 |
+
"pad_token": "[PAD]",
|
| 13 |
+
"sep_token": "[SEP]",
|
| 14 |
+
"subword_tokenizer_type": "wordpiece",
|
| 15 |
+
"sudachi_kwargs": null,
|
| 16 |
+
"tokenizer_class": "BertJapaneseTokenizer",
|
| 17 |
+
"unk_token": "[UNK]",
|
| 18 |
+
"word_tokenizer_type": "mecab"
|
| 19 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:16da3b2cbdab6ab8867f55ec7f7b9da78660783d9ac3f20f4280d2499c5ef288
|
| 3 |
+
size 4079
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|